小霍学科研 Meta分析与可视化平台
提供传统 Meta 分析、诊断试验网状 Meta 分析、贝叶斯/频率学 NMA、GRADE 评级和质量评价工具,帮助研究者更高效地完成数据整理、统计分析和论文图表输出。
服务内容
平台面向医学科研、循证评价、诊断试验和网状 Meta 分析场景,提供网页化分析入口与规范化输出。
统计分析工具
支持传统 Meta、诊断型 Meta、贝叶斯 NMA、频率学 NMA、剂量反应 Meta 和三水平 Meta。
论文图表输出
生成森林图、SROC、漏斗图、SUCRA 排名、联赛表、GRADE 表和可下载图表。
系统评价辅助
提供 PRISMA、NOS、QUADAS、ROBUST-RCT、PROBAST+AI 等质量评价与模板支持。
真实输出预览
系统评价流程与证据质量
保留 PRISMA、GRADE 和质量评价这类系统评价入口,但每个图只出现一次。
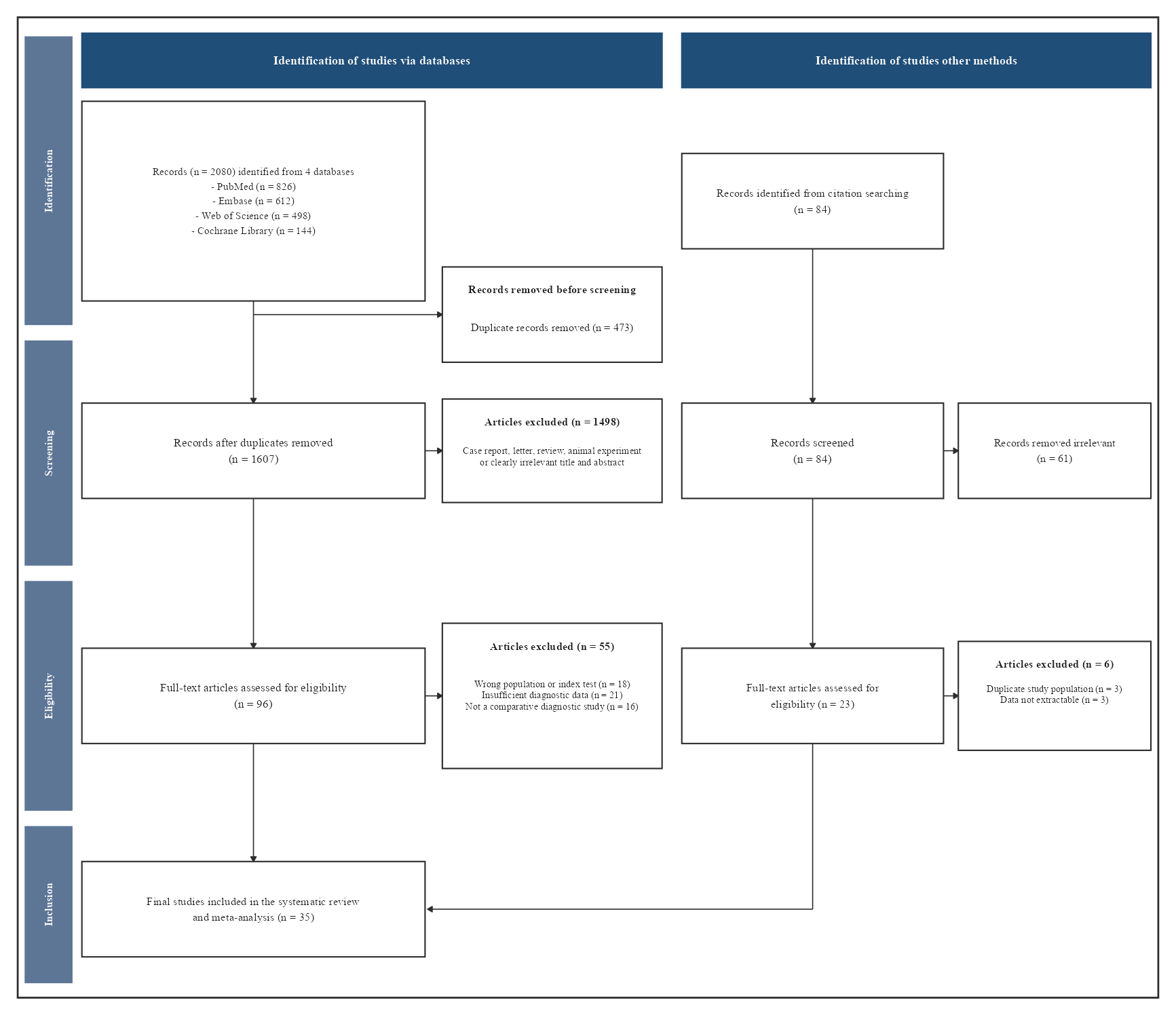
来自 PRISMA 模块的识别、筛选、合格性和纳入流程输出。

展示结局、效应估计和证据确定性的图形化证据表。
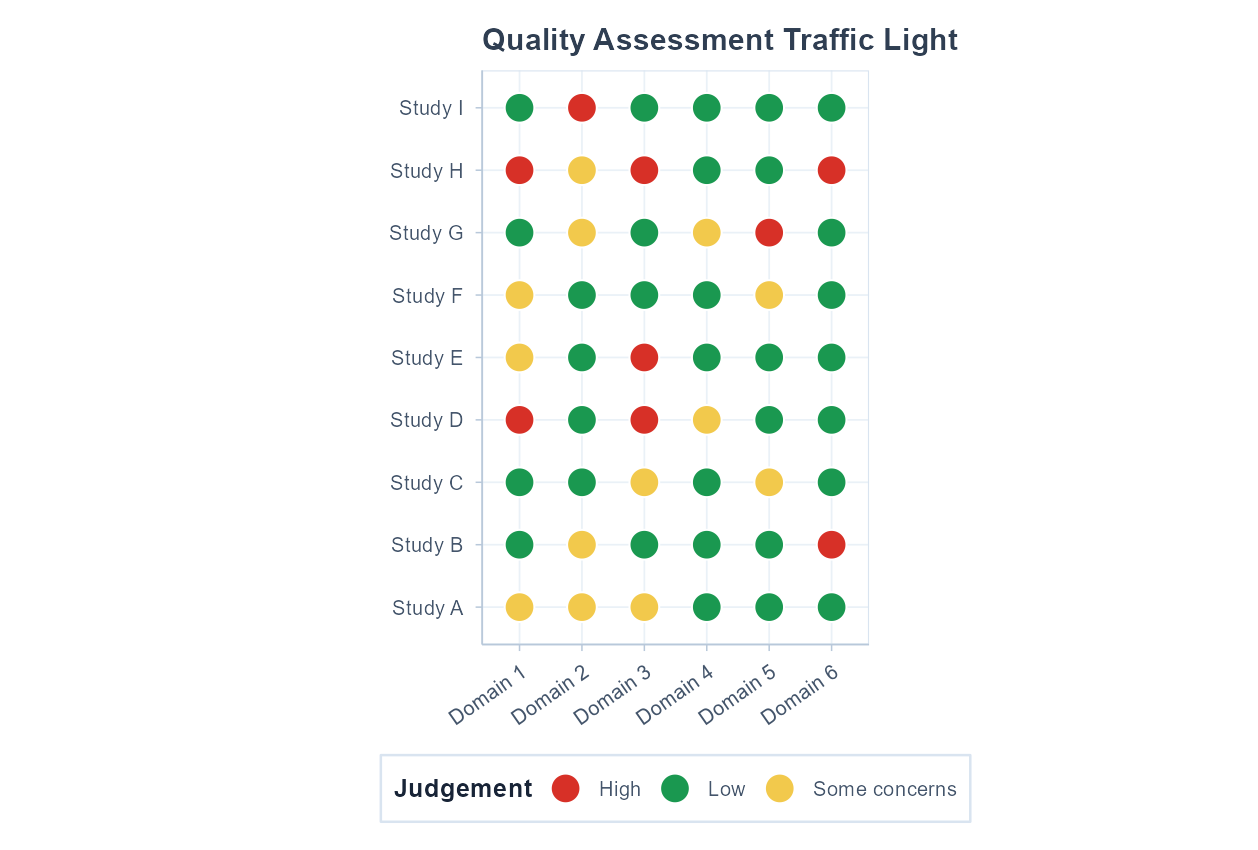
呈现各研究在不同偏倚风险维度上的逐项判断。
传统 Meta 分析
覆盖二分类、连续型和预合并数据常用的森林图、偏倚探索和稳健性检查。
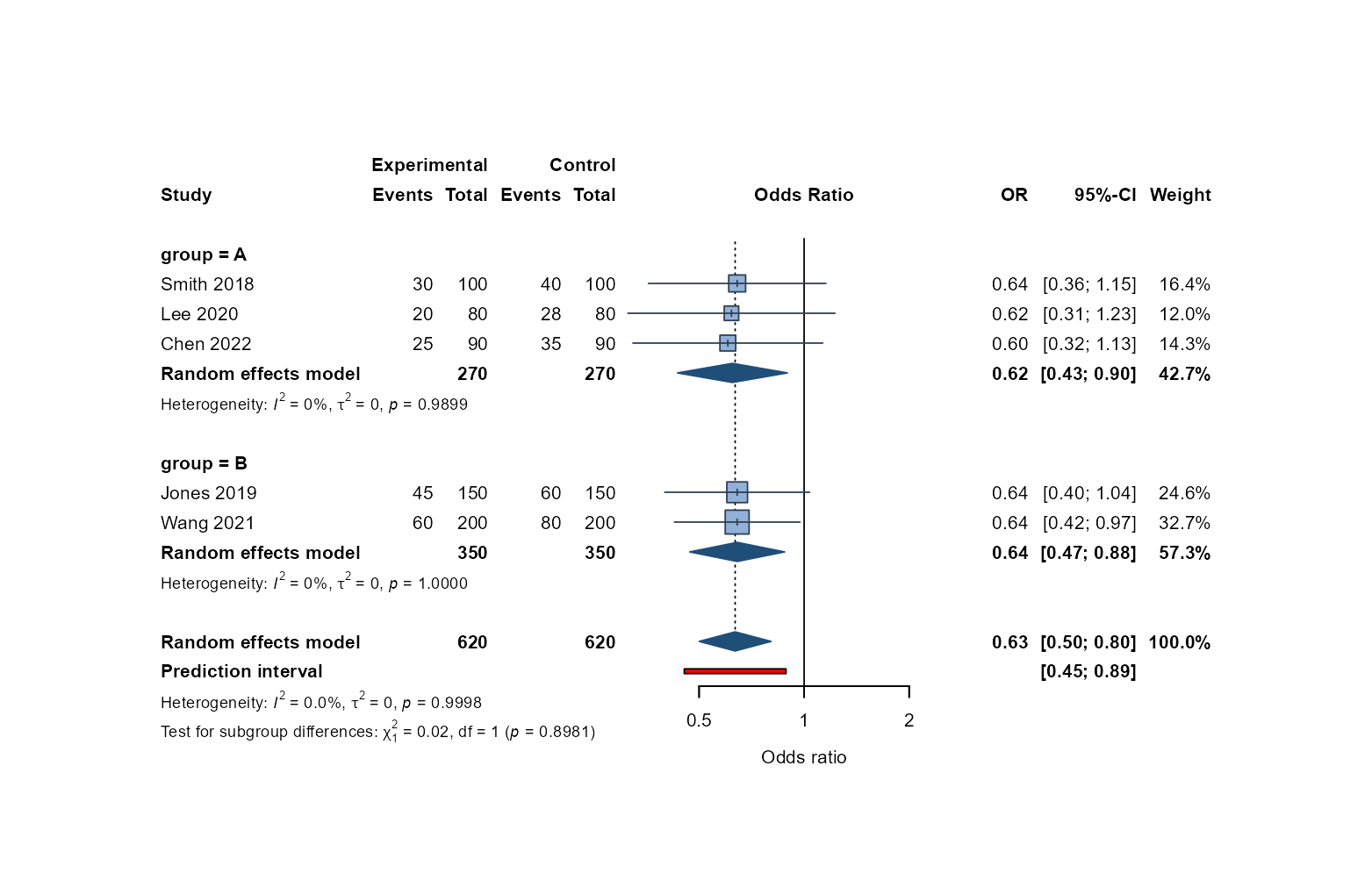
显示单项研究、合并效应、预测区间和权重信息。
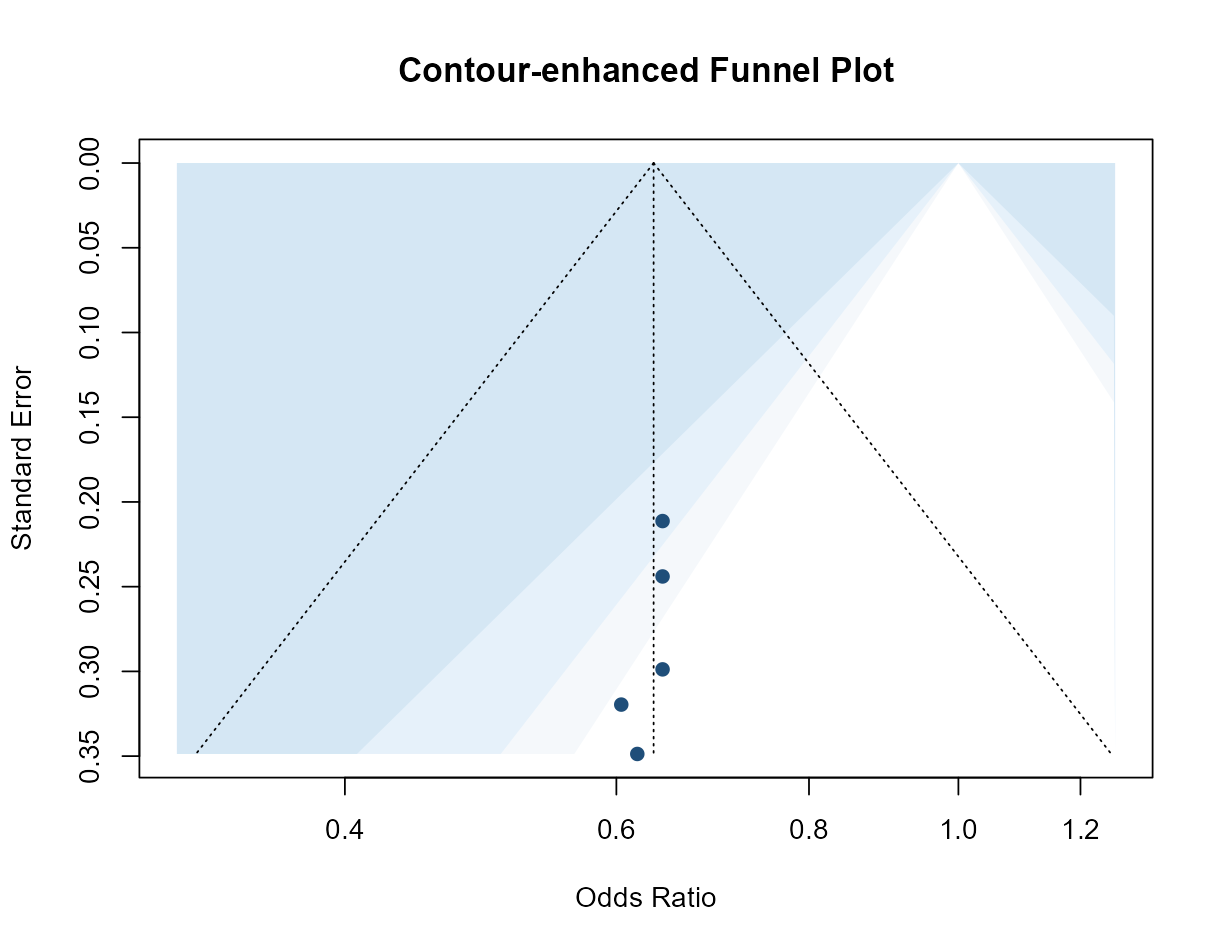
用显著性轮廓辅助判断发表偏倚与小样本效应。
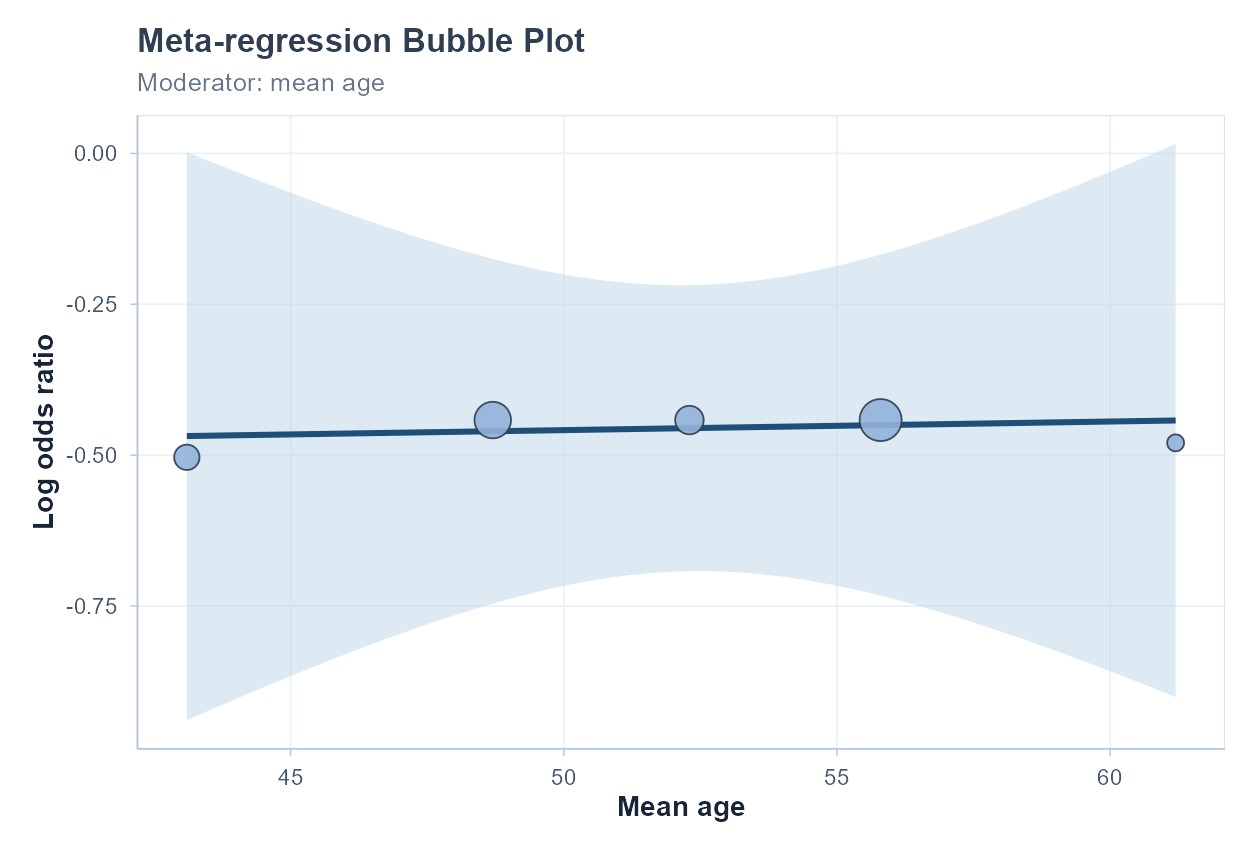
以研究权重气泡展示协变量与效应量之间的趋势。
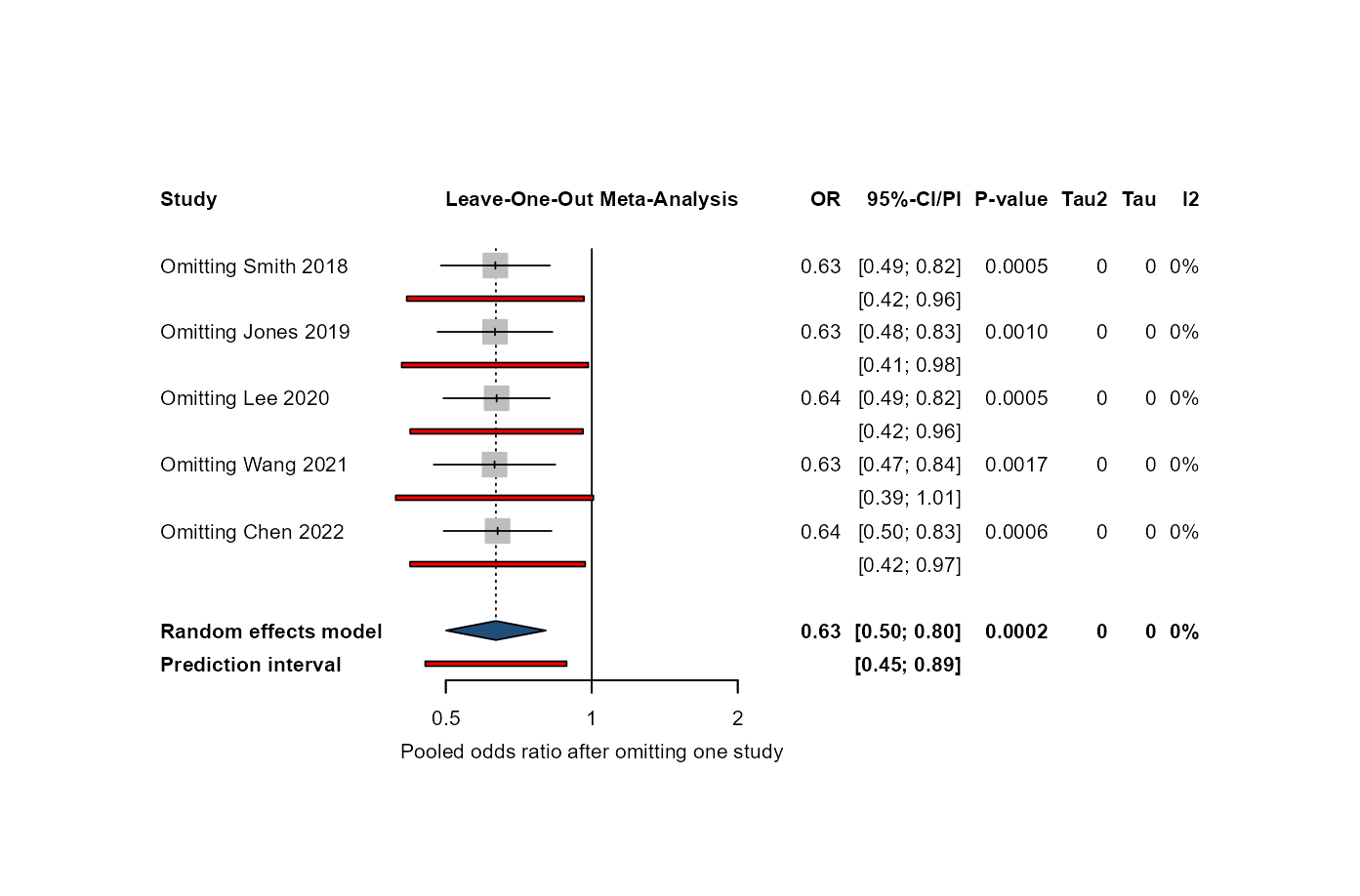
逐项排除研究后检查合并效应是否稳定。
诊断准确性 Meta 分析
突出诊断型研究最常用的 Se/Sp、SROC、临床概率转换和发表偏倚评估。
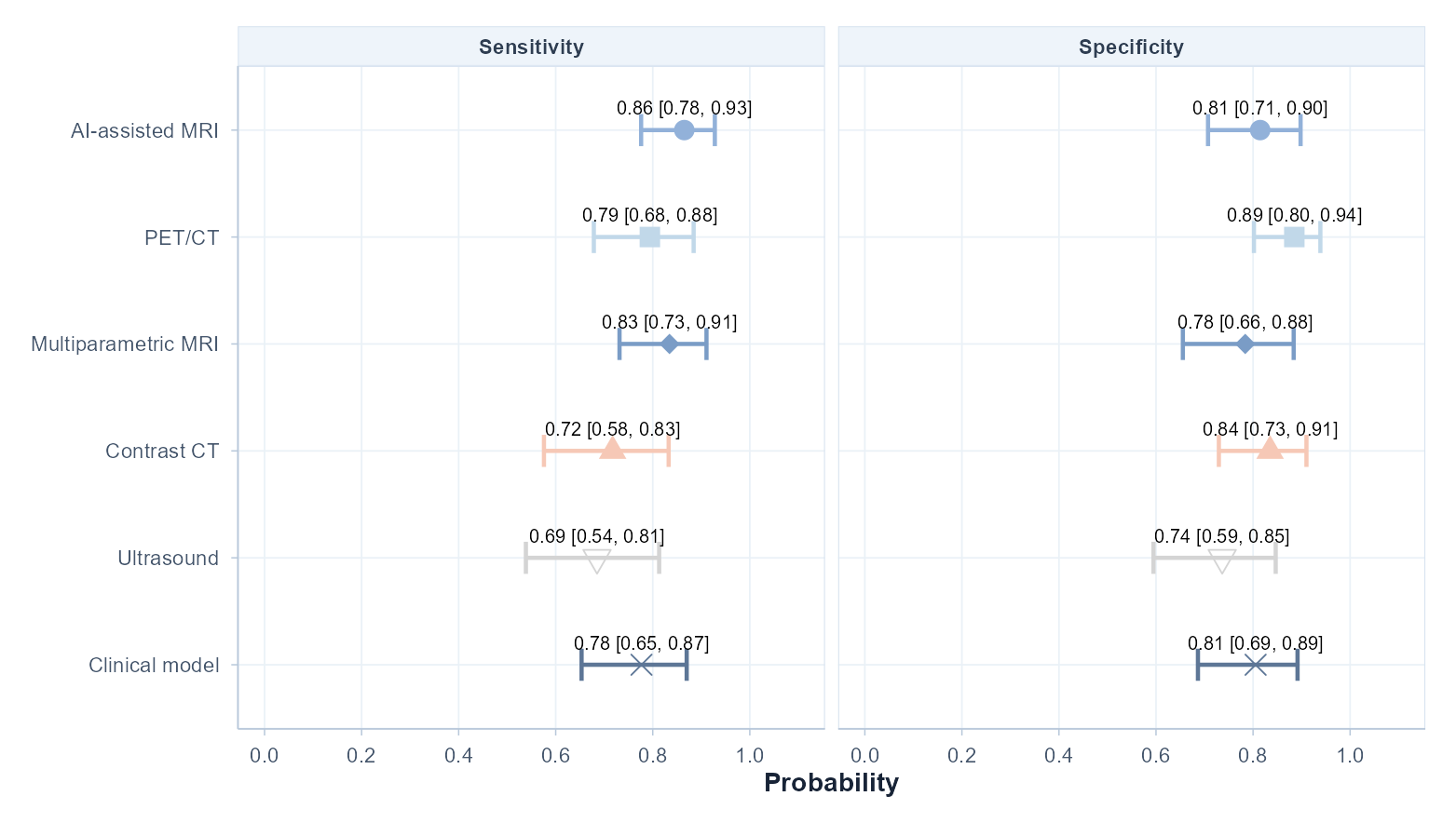
并列展示敏感性、特异性及其不确定性区间。
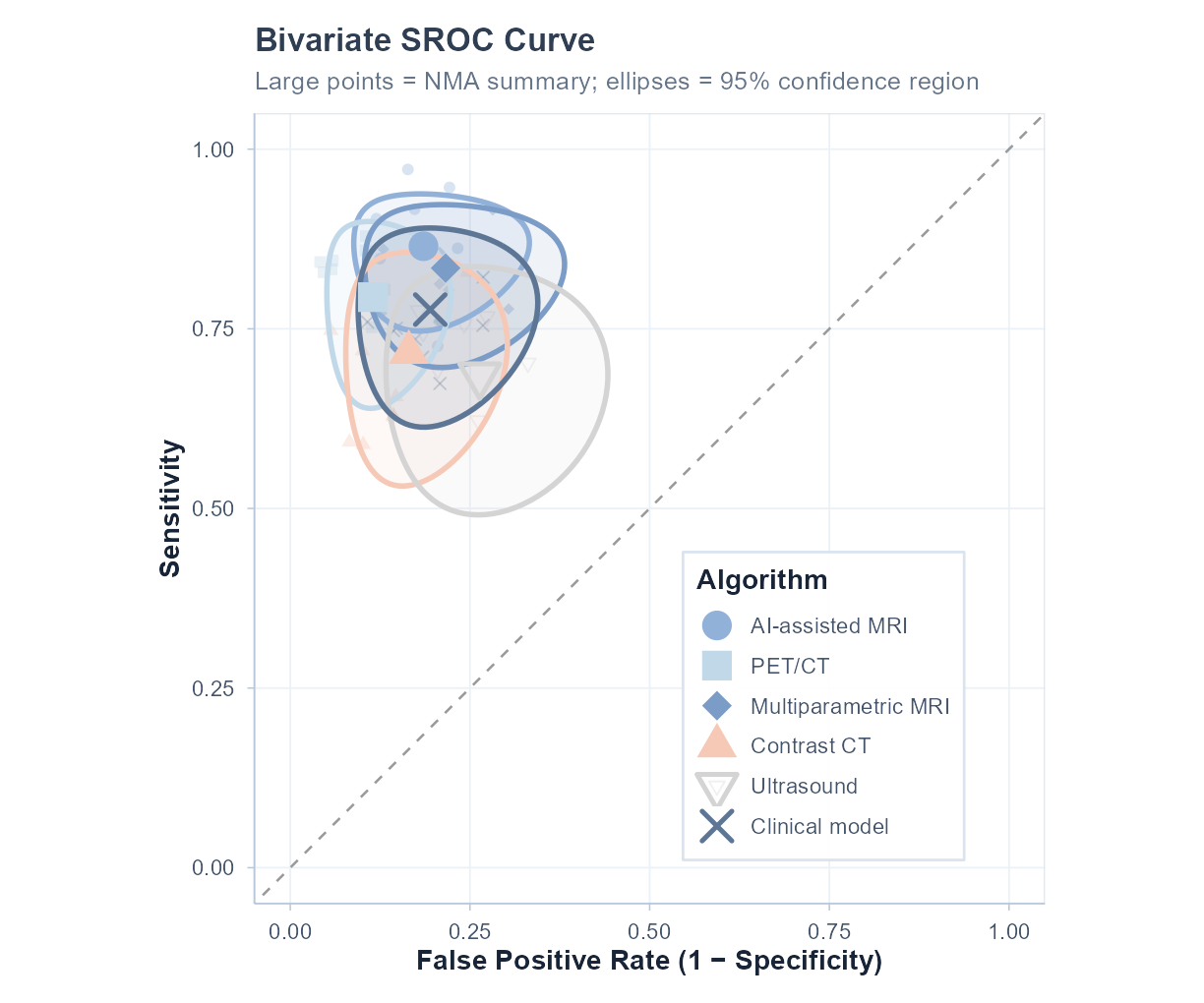
汇总诊断准确性研究中的敏感性与特异性表现。
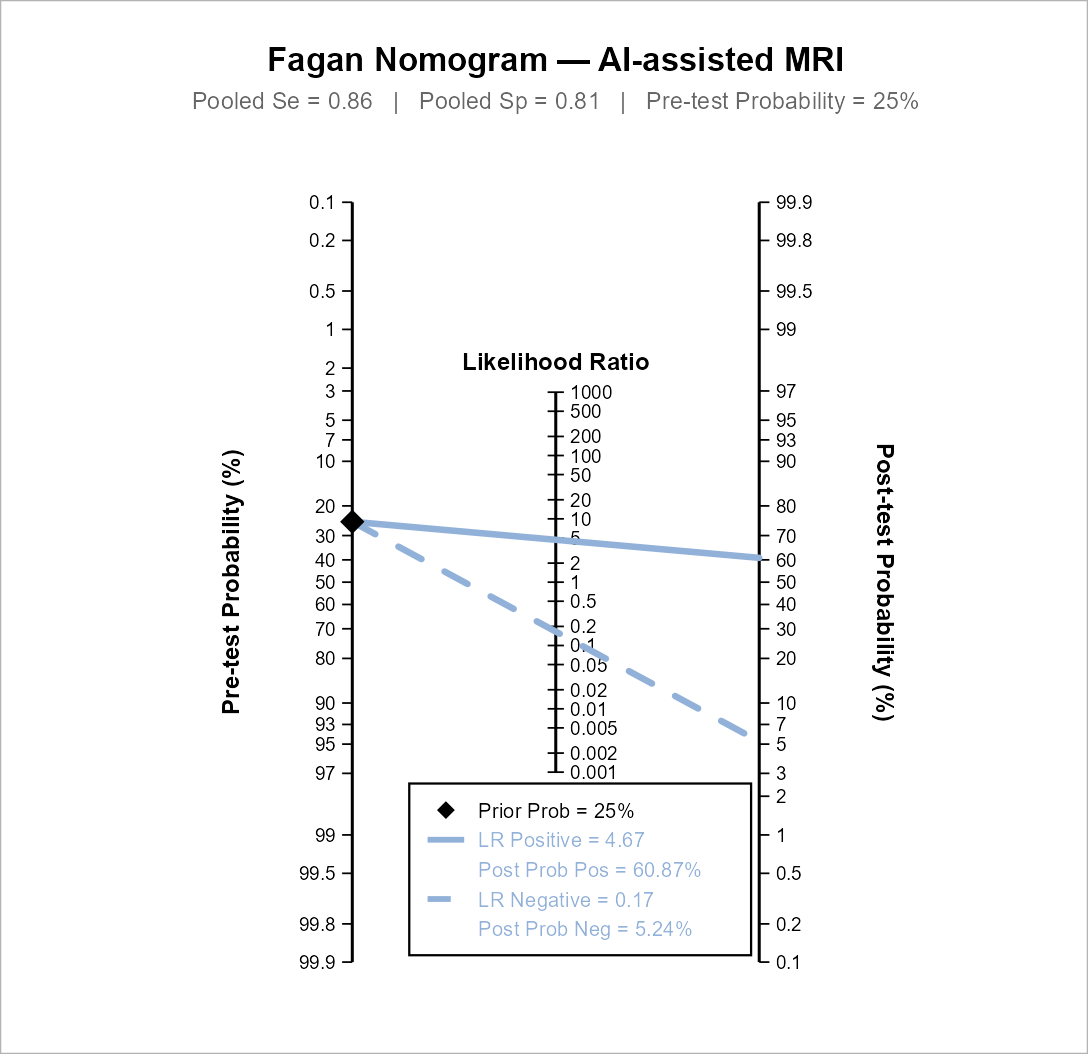
把检验前概率、似然比和检验后概率连成临床解释链。
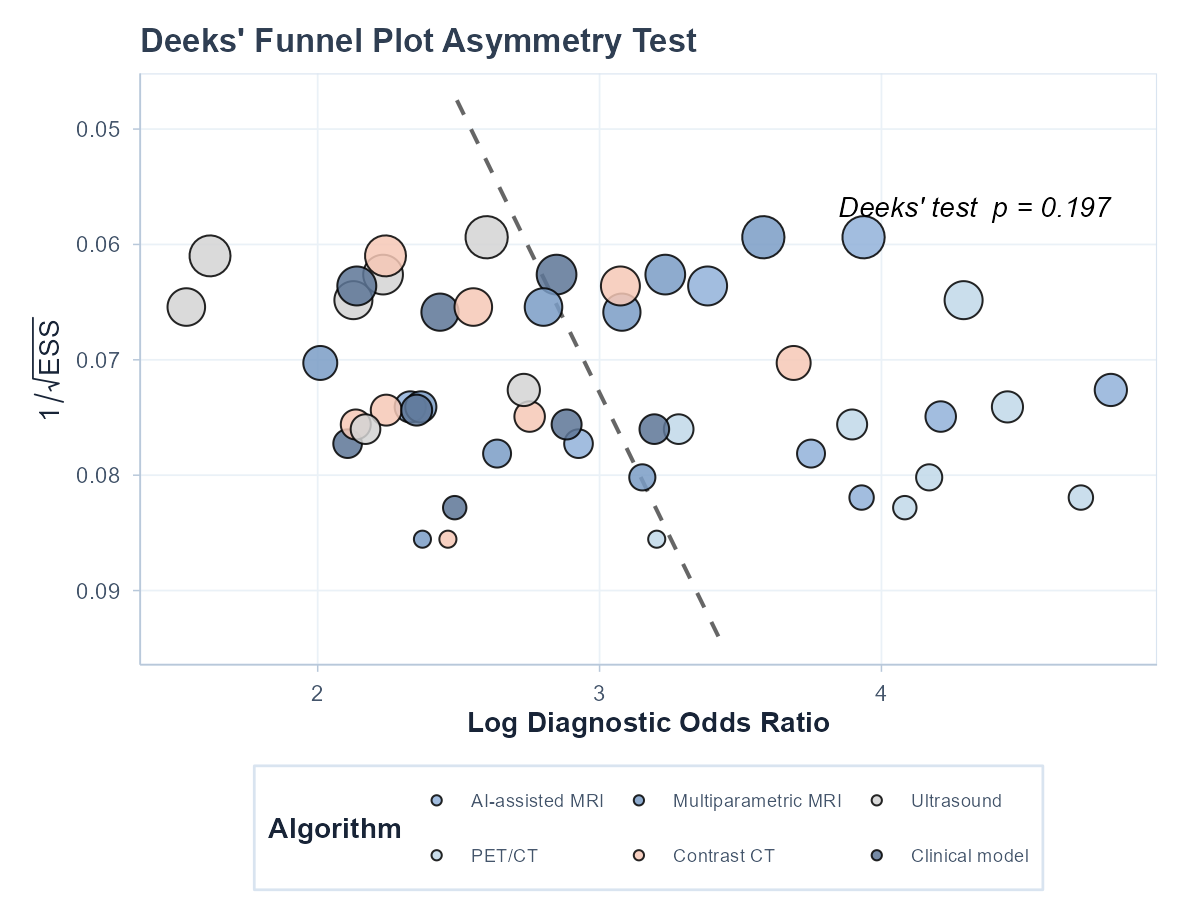
用于诊断准确性 Meta 分析的发表偏倚评估。
诊断试验网状 Meta 分析
展示诊断策略或算法之间的网络结构、排序、联赛表和临床决策输出。
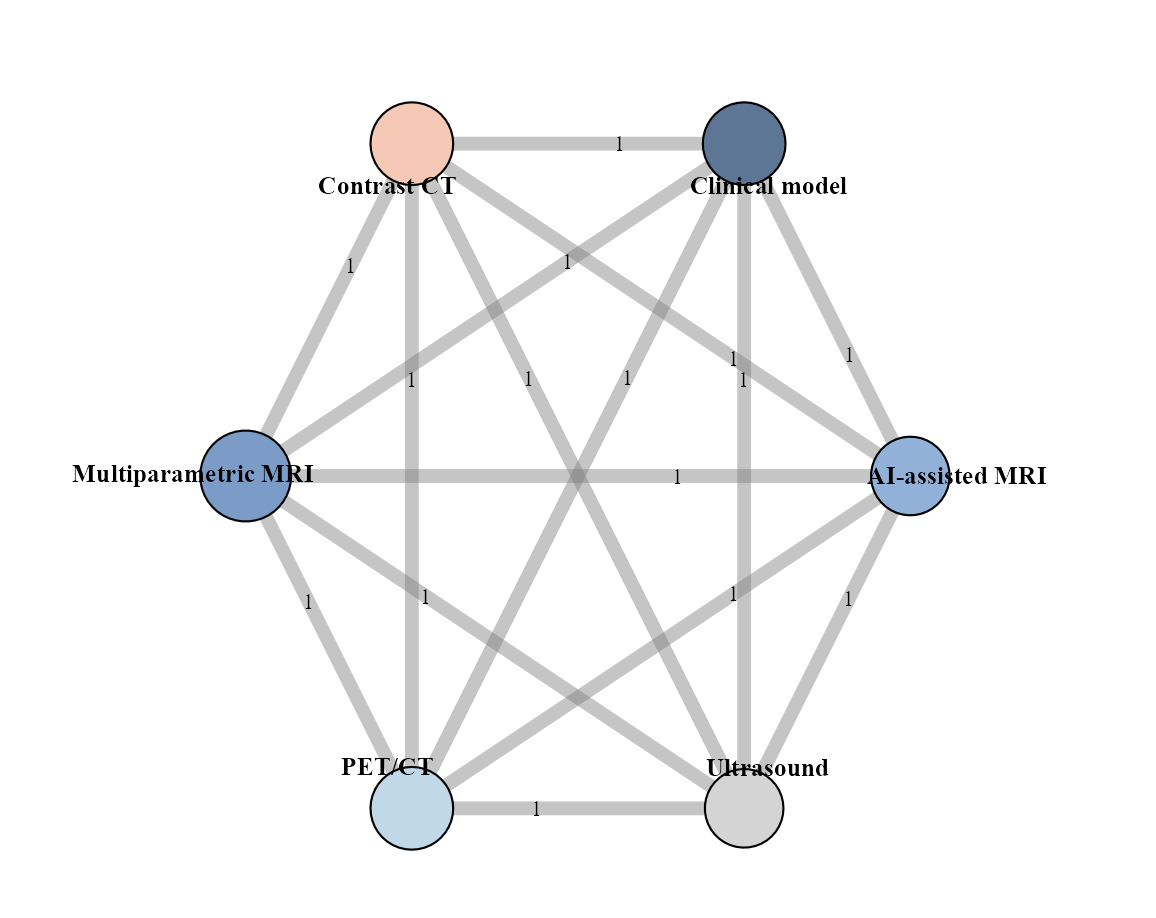
展示不同诊断策略之间的直接比较结构和边权重。
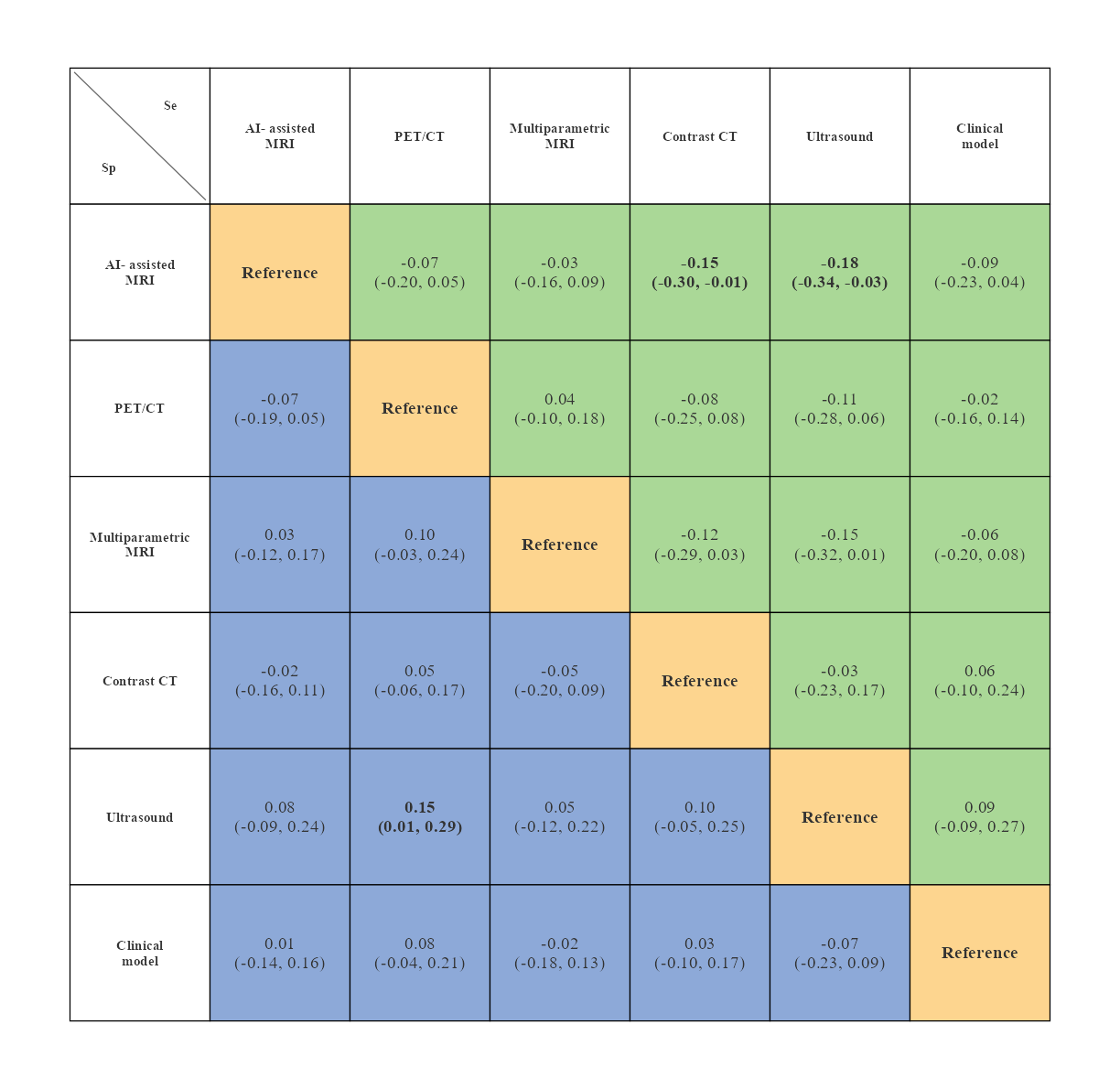
以矩阵形式汇总各诊断策略的敏感性和特异性相对差异。
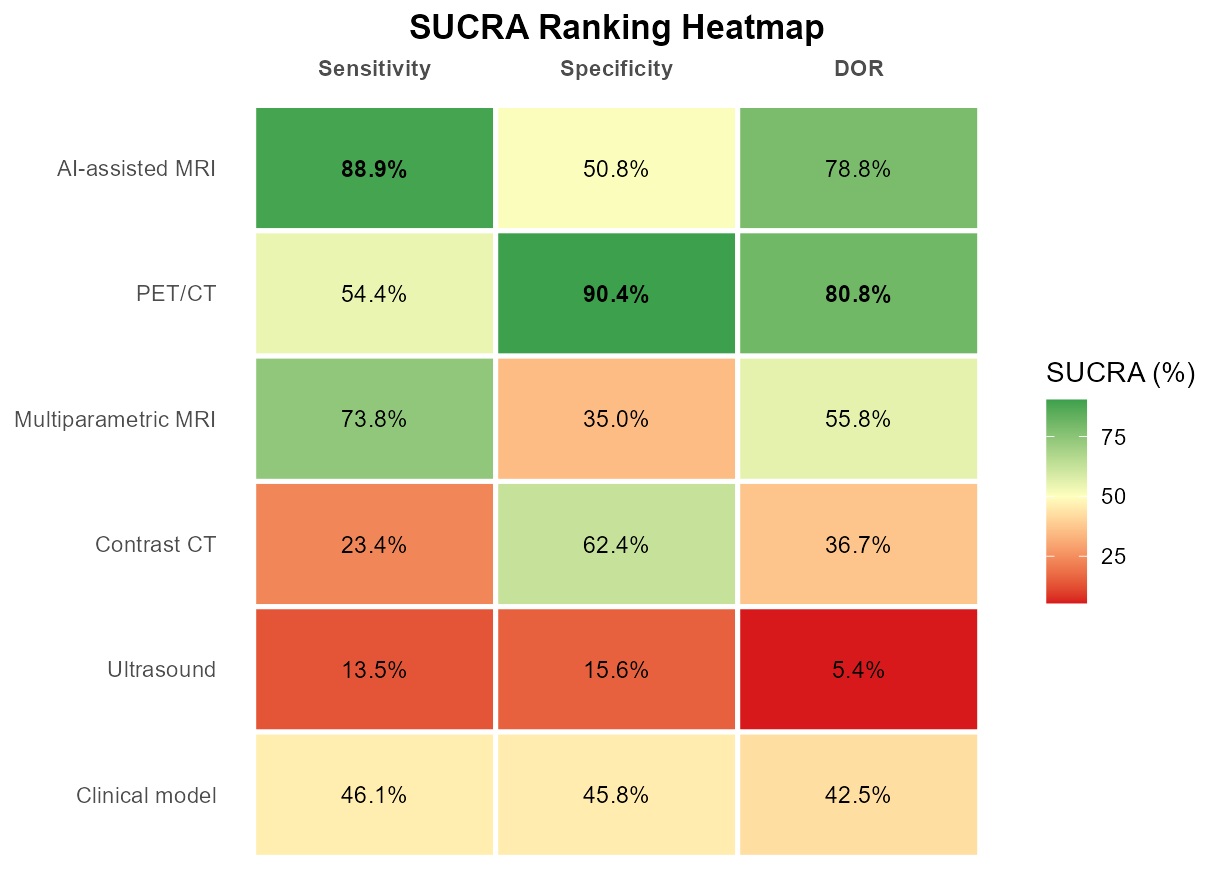
比较各诊断策略在 Se、Sp 和 DOR 维度上的排序概率。
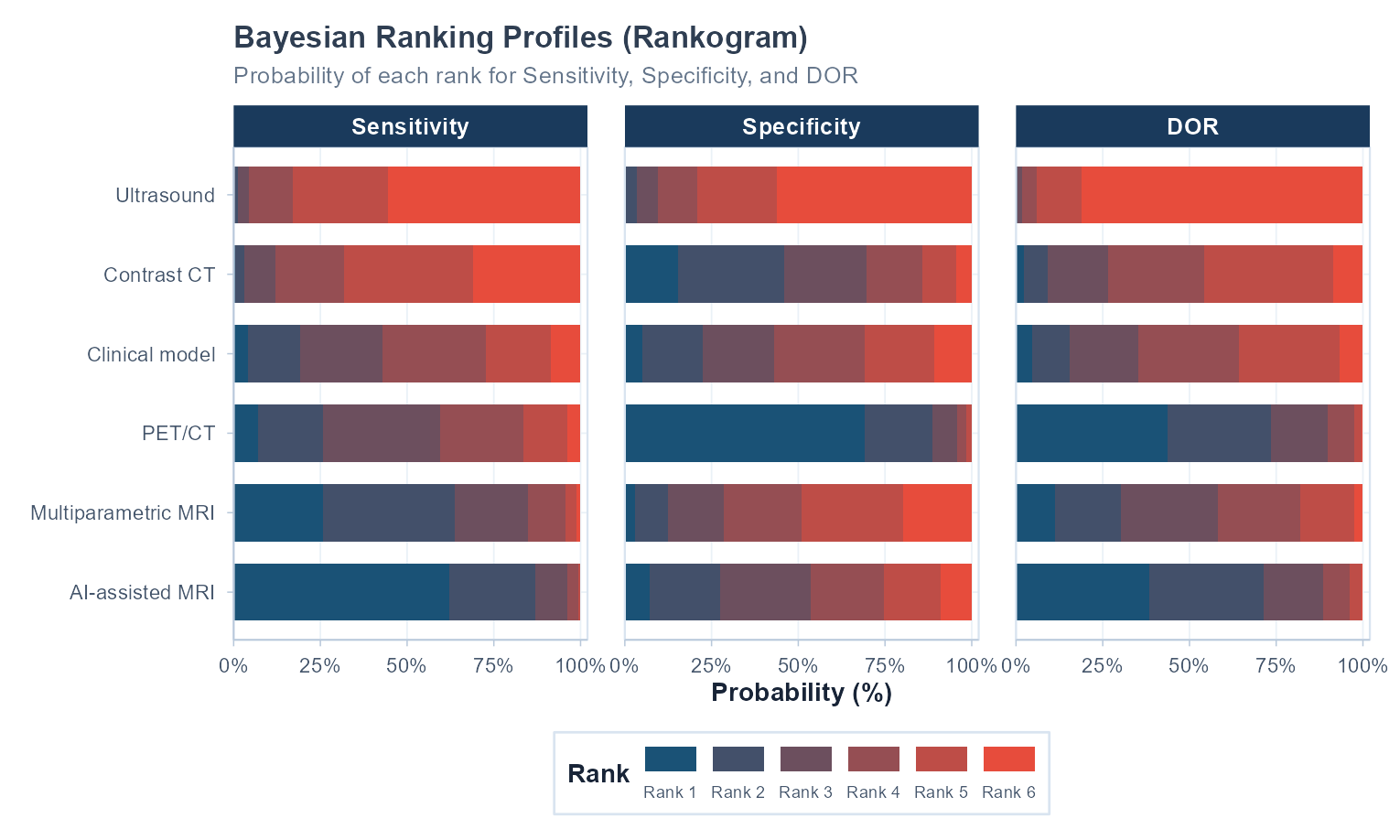
保留每种策略在各排名位次上的完整概率分布。
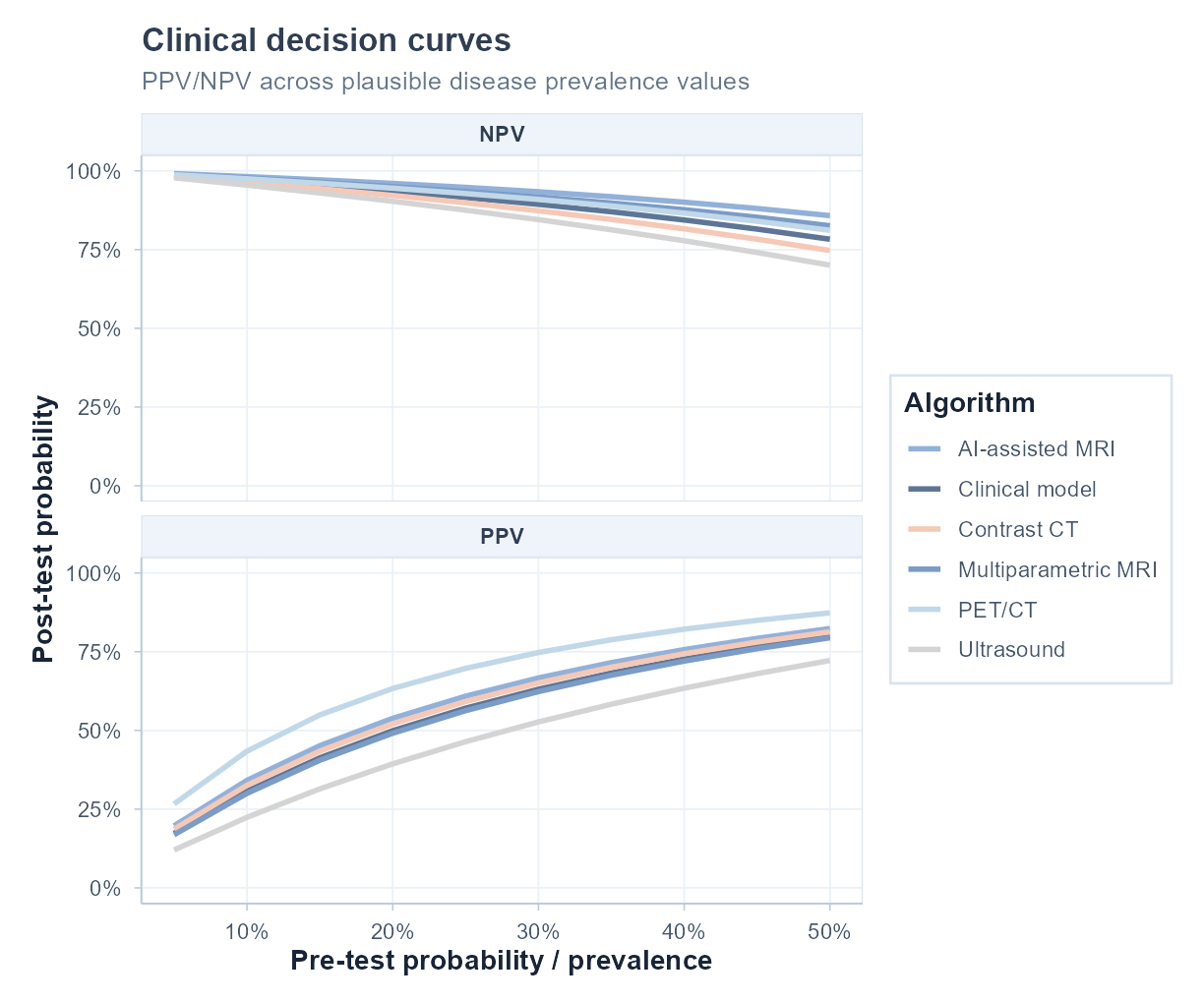
在不同患病率下显示 PPV/NPV 的临床可解释输出。
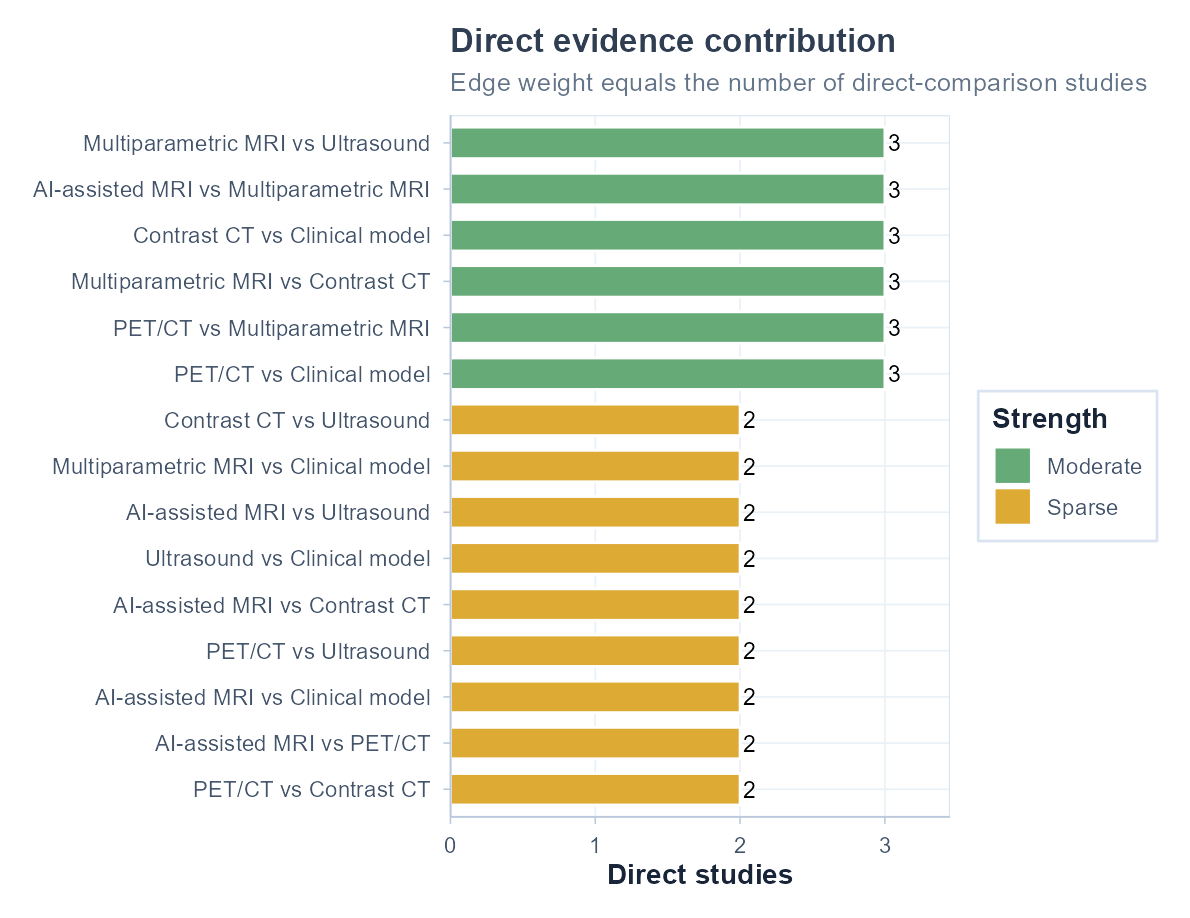
按直接比较数量呈现网络证据的强弱分布。
干预型网状 Meta 分析
覆盖贝叶斯和频率学 NMA 常见的网络、排序和比较调整漏斗图。
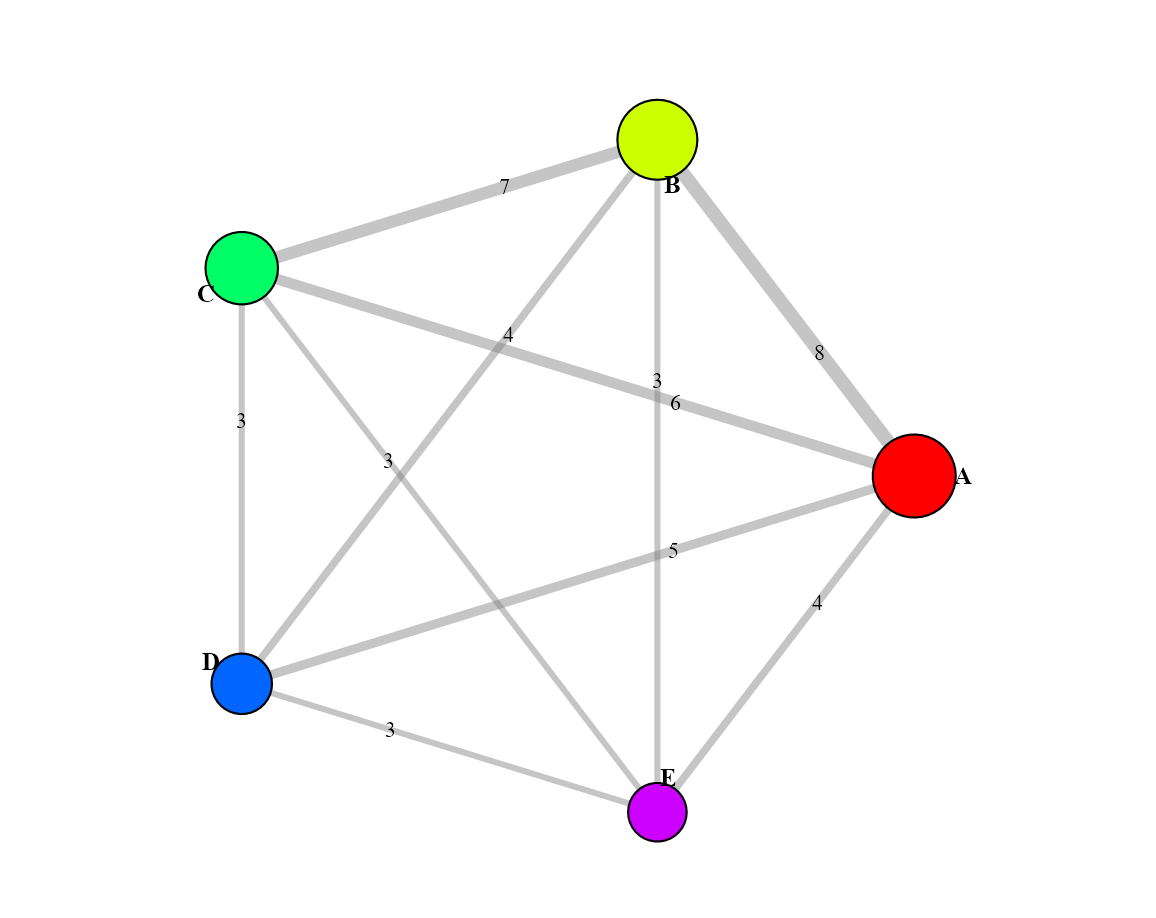
显示治疗节点、直接比较边和纳入研究数量。
展示不同治疗达到前若干名排序的累计概率。
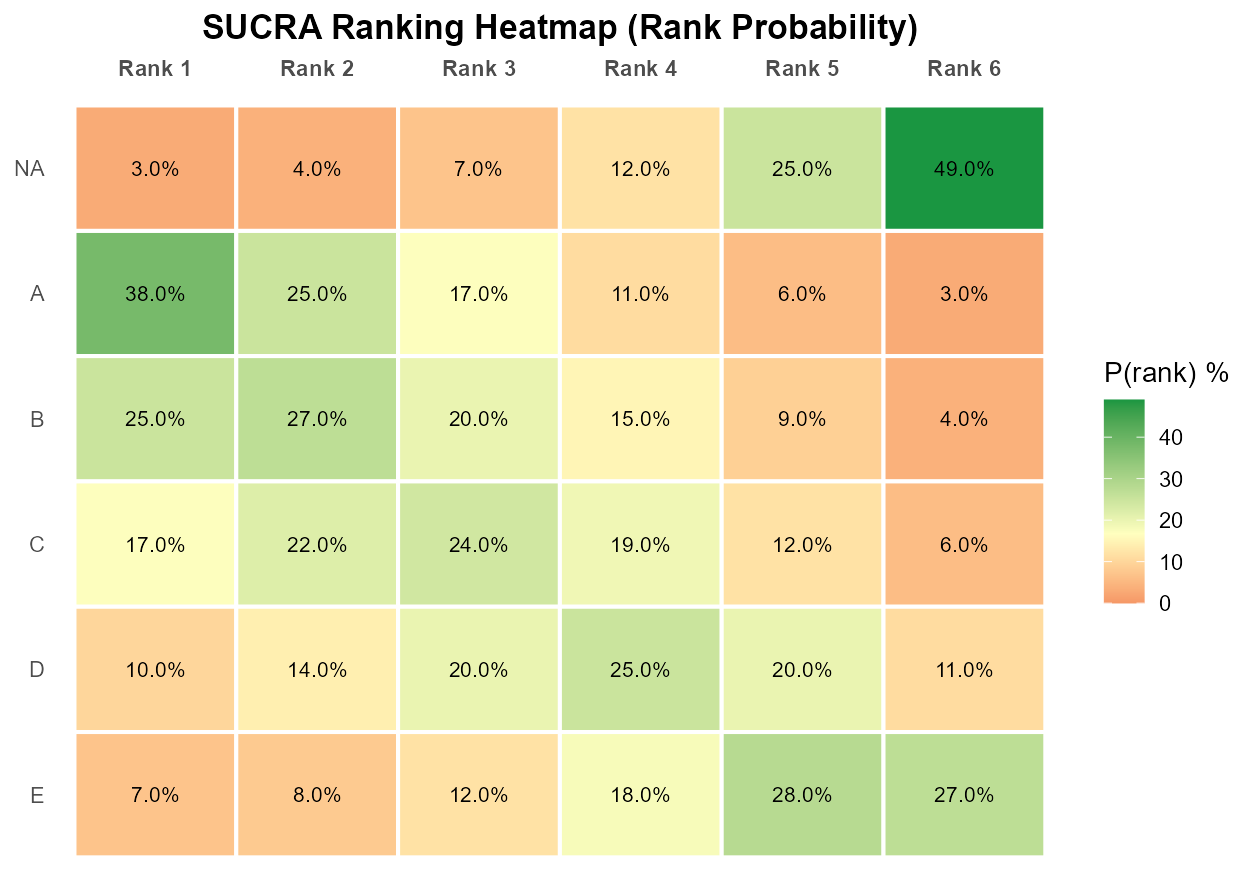
以热图呈现各治疗在不同名次上的排序概率。
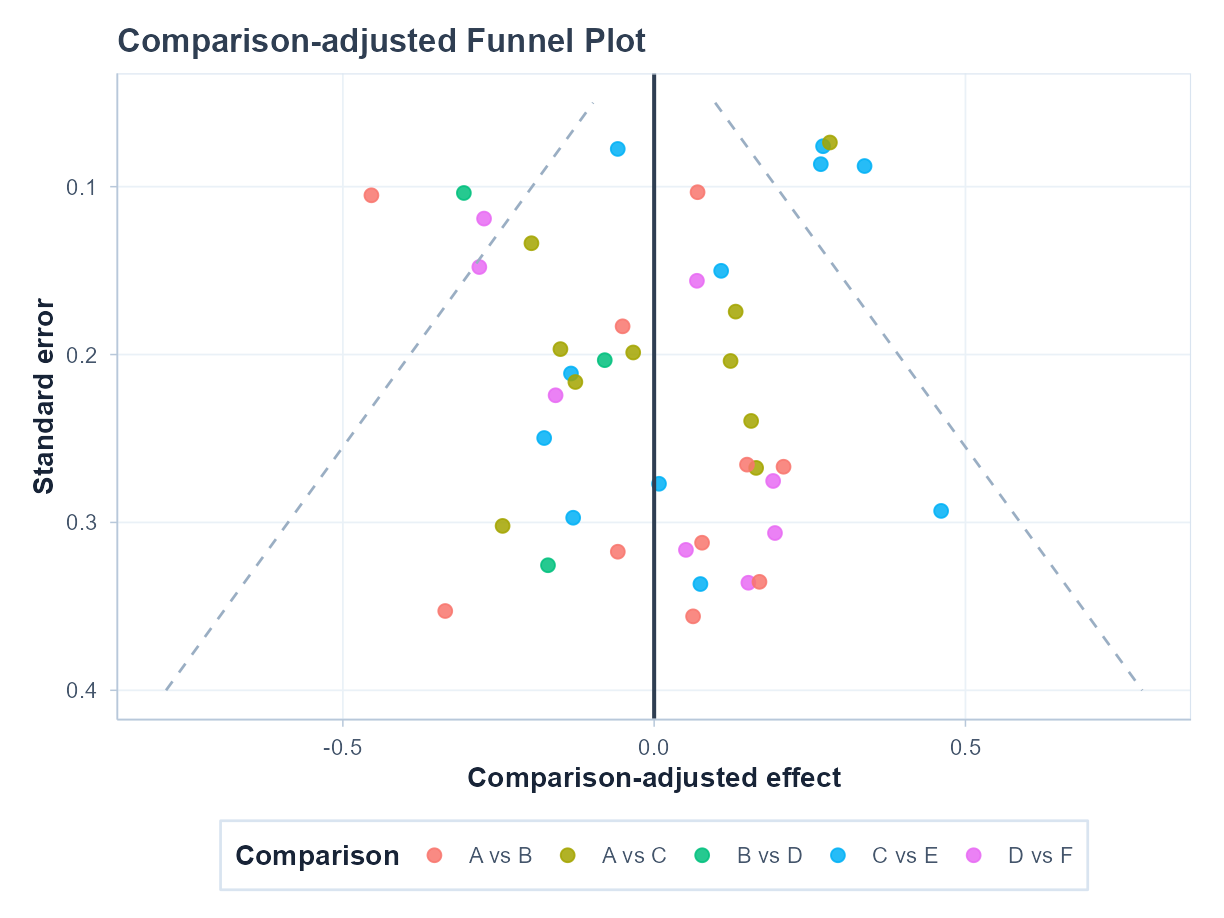
用于网状 Meta 分析中的小样本效应和发表偏倚探索。
扩展 Meta 模型
补充剂量反应、三水平 Meta 和预测模型汇总,让首页更能体现平台覆盖面。
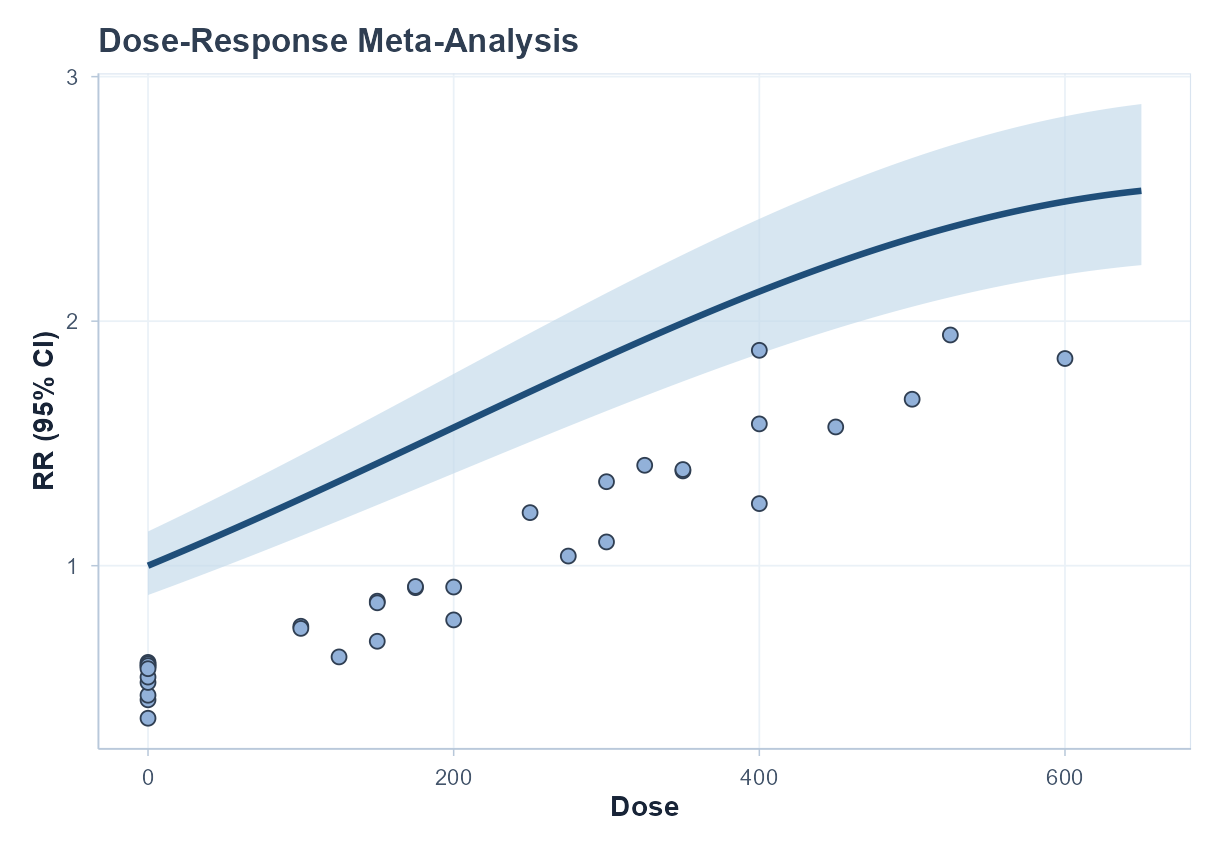
展示暴露剂量与效应变化之间的非线性趋势。
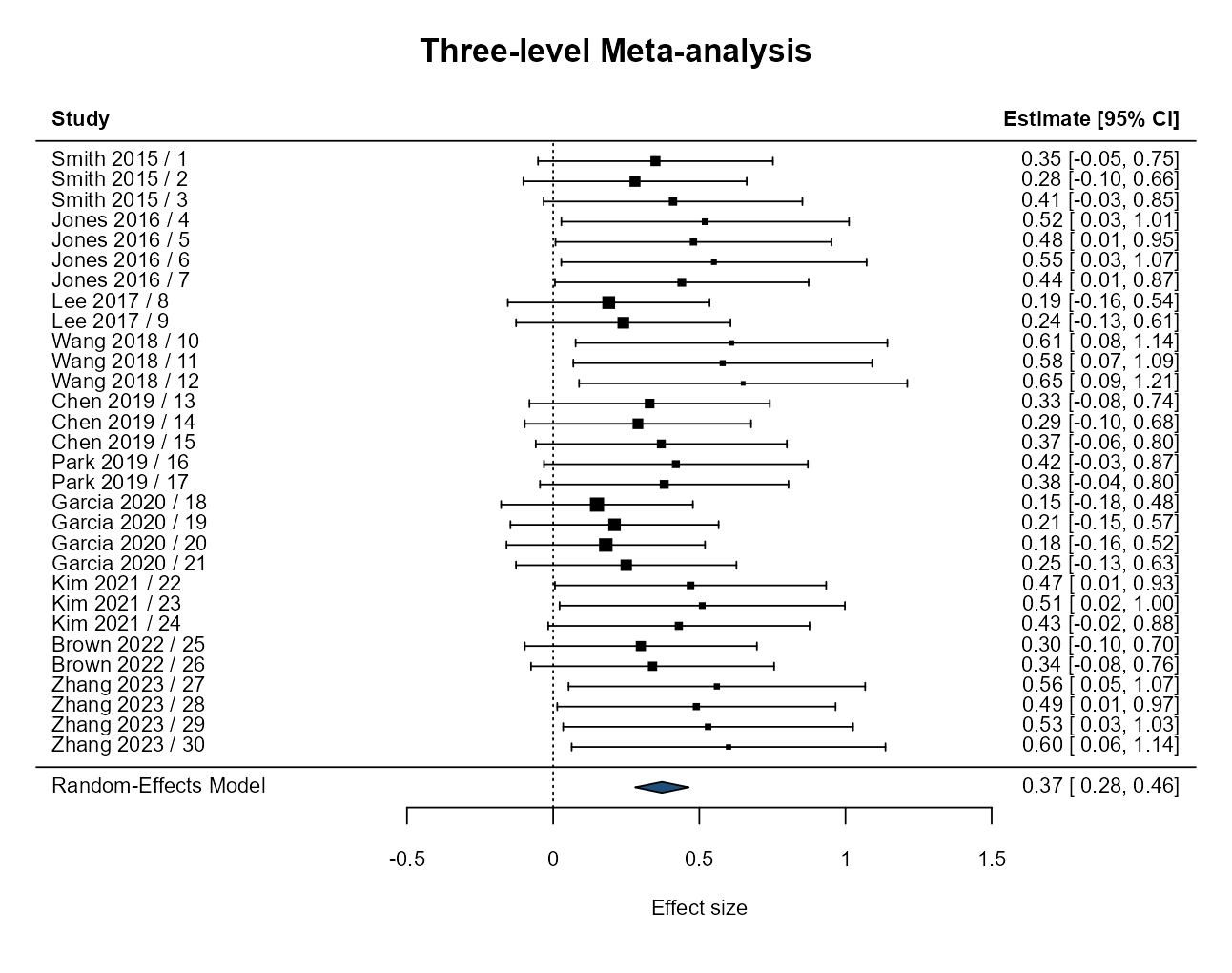
适合一个研究内含多个相关效应量的层级模型。
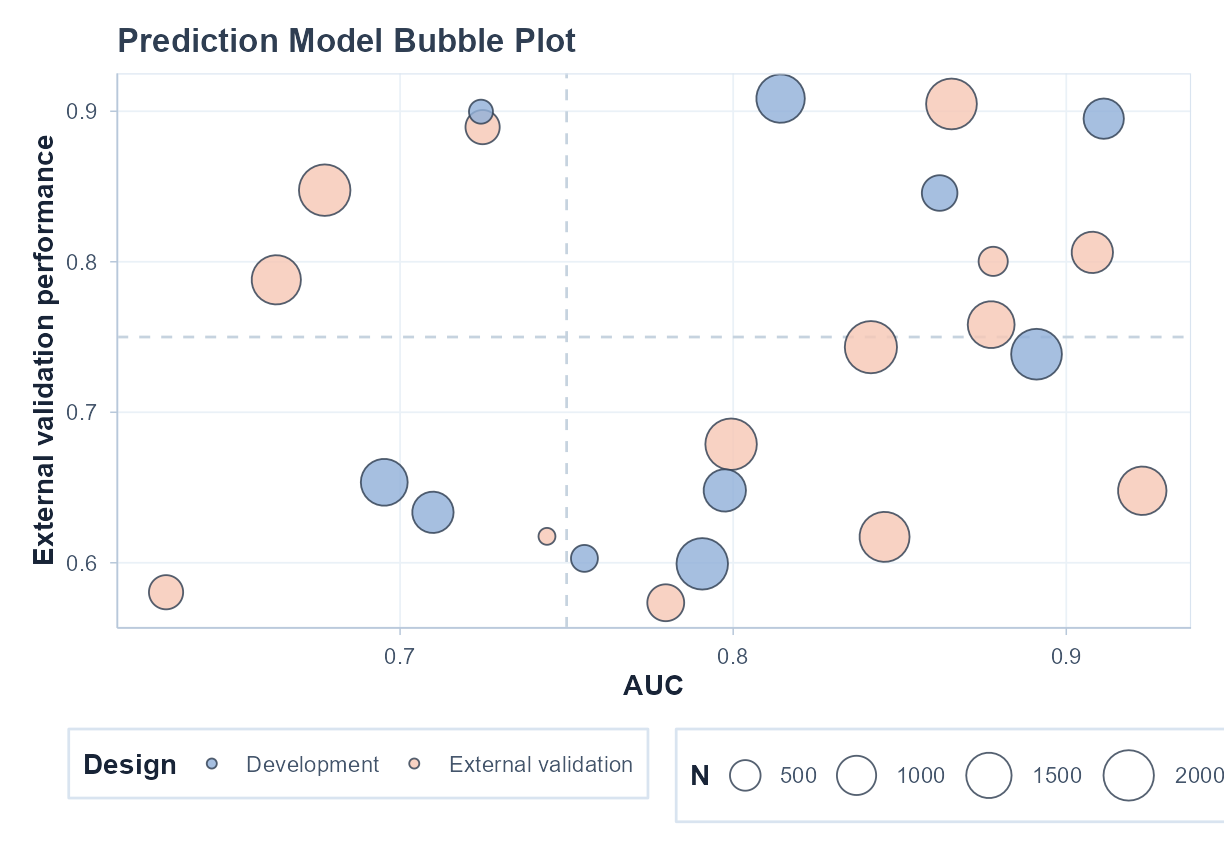
汇总模型区分度、外部验证表现和研究规模。
联系方式
如需开通会员、科研咨询、模板支持或平台使用协助,可通过微信二维码联系。
主体名称:深圳市松术教育咨询有限公司
 微信咨询 / 会员开通
微信咨询 / 会员开通
小霍学科研 Meta 分析平台
科研咨询 / 模板支持
传统Meta分析
二分类、连续型、诊断型配对 Meta。森林图、漏斗图与敏感性分析。
2 个子模块 进入 →网状Meta分析
诊断型、贝叶斯与频率学 NMA。支持 HR/OR/RR 与排序分析。
7 个子模块 进入 →系统评价工具
PRISMA、QUADAS-3、NOS、ROBUST-RCT、PROBAST+AI。
5 个通用工具 进入 →GRADE等级评分
RCT GRADE、偏倚风险热图与 SoF 汇总。
4 个分析页面 进入 →PICOS 要素
结构化输出
数据格式要求
-
s— 研究编号(数字或字符均可) -
algo— 算法标识(任意字符均可,如 A/B/C 或 1/2/3 等,个数不限) -
tp,fp,fn,tn— 四格表数据
同一研究中可包含多种算法(多臂设计)。 每行对应一个「研究×算法」组合。
下载示例 CSV方法学依据
- Ma X et al. (2018). Biostatistics 19(1):87-102 — 双变量随机效应DTA-NMA框架
- Verde PE. (2010). Statistics in Medicine 29:3088-3102 — 尺度混合正态先验(异常研究检测)
- Owen RK et al. (2018). J Clin Epidemiol 99:64-74 — 多臂研究处理
- Dias S et al. (2010). Statistics in Medicine — Node Splitting 一致性检验
数值汇总表
异质性参数
Bayesian Ranking Profiles(贝叶斯排名概率图)
收敛诊断表 (R-hat < 1.05; ESS > 1000 为良好)
注意: 若数据不含该列,将提示错误。
方法学说明 — 基于臂级(Arm-Level)的 Meta 回归
本平台的网状 Meta 回归采用
基于臂级(arm-level)的广义线性混合模型(GLMM)
,协变量以臂为单位赋值(
cov[i]
),而非在研究层面进行汇总。通过引入研究特异性随机效应(
u_se[s[i]]
和
u_sp[s[i]]
),模型在估计过程中自然保留了研究内部的比较信息。
这种臂级建模方式使模型能够充分利用研究内部的变异
(例如,同一研究中某算法在内部验证集、另一算法在外部验证集上进行评估),
从而严格校正研究层面的混杂因素,避免生态学偏倚。
为保证模型收敛并防止参数过多,本模型对所有诊断算法采用
共同交互假设
,即灵敏度(
γse
)和特异度(
γsp
)各估计一个全局 Meta 回归系数。
示例说明 — 内部验证集 vs. 外部验证集
假设某项研究同时评估了两种算法,但分别在不同数据集上进行验证:
| 臂(数据行) | 算法 | 协变量(design) | 含义 |
|---|---|---|---|
| 研究5,臂 A |
算法X
|
internal | 在训练集 / 内部验证集上测试 |
| 研究5,臂 B |
算法Y
|
external | 在独立的外部验证队列上测试 |
在此情境下,
cov[i]
对臂 A 取值
"internal"
,对臂 B 取值
"external"
,两者属于同一研究。
臂级模型可直接捕捉这种研究内部的对比,估计诊断准确性在内部验证与外部验证场景下的差异——
而研究级模型(每项研究仅赋一个协变量值)无法识别这种差异。
Meta 回归设置
例如: design, year, quality, region
Select Algorithm
Upload data to view per-algorithm results (no NMA run required).
1. 森林图展示该算法在各研究中的灵敏度、特异度和 DOR(95% CI)。
2. Deeks 漏斗图用于评估该算法的发表偏倚;p < 0.10 提示可能存在偏倚。
3. Fagan 图展示先验概率如何通过 LR+ / LR− 转换为阳性或阴性结果后的后验概率。
传递性协变量
一致性总览表
每1000人绝对结果图
不一致性、不精确性、发表偏倚均根据 NMA 结果自动计算。
注意: 需先完成 NMA 主要结果运算后再生成 GRADE 表。
评分设置
为每个算法选择偏倚风险与间接性降级等级(0 = 不降级,-1 = 降 1 级,-2 = 降 2 级)
留空则不显示每1000例效应
GRADE 证据质量评级
PRISMA 参数设置
PRISMA 流程图预览
数据与设置
AUC 气泡图
Settings
Radar / Circular Bar Chart
Settings
Risk Level Colors
PROBAST+AI Quality Assessment
方法学依据 (Methodological Basis)
工具简介
PROBAST+AI(Prediction model Risk Of Bias ASsessment Tool for Artificial Intelligence)是在原版 PROBAST(2019)基础上更新的工具,专为评估使用回归或 AI/机器学习方法的预测模型研究的 方法学质量、偏倚风险与可适用性 而设计。2025 年 3 月发表于 BMJ,适用于系统评价者、模型开发者、期刊编辑及临床决策者。
核心评估框架
- [a] 参与者与数据源:数据来源、研究设计、代表性
- [b] 预测因子:定义一致性、预处理、可获得性
- [c] 结局:定义适当性、盲法评估
- [d] 分析:样本量、缺失数据、过拟合防控
- [e][f][g] 可适用性:三域均评估
- [a] 参与者与数据源(同开发)
- [b] 预测因子(同开发)
- [c] 结局(同开发)
- [d] 分析(新增7题):数据泄漏、重采样、性能评估完整性
- [e][f][g] 可适用性:三域均评估
相较 PROBAST 2019 的核心更新
①扩展至 AI/机器学习方法(随机森林、神经网络、支持向量机等);②新增超参数调优、类不平衡处理、数据泄漏评估;③新增算法公平性考量;④样本量评估细化为开发与评估两阶段专项指导。
支撑文献
- PROBAST+AI(主文献): Moons KGM, Damen JAA, Kaul T, et al. PROBAST+AI: an updated quality, risk of bias, and applicability assessment tool for prediction models using regression or artificial intelligence methods. BMJ . 2025;388:e082505. DOI: 10.1136/bmj-2024-082505
- 原版 PROBAST(工具论文): Wolff RF, Moons KGM, Riley RD, et al. PROBAST: A Tool to Assess the Risk of Bias and Applicability of Prediction Model Studies. Ann Intern Med . 2019;170(1):51–58. DOI: 10.7326/M18-1376
- PROBAST 详解与解读: Moons KGM, Wolff RF, Riley RD, et al. PROBAST: A Tool to Assess Risk of Bias and Applicability of Prediction Model Studies: Explanation and Elaboration. Ann Intern Med . 2019;170(1):W1–W33. DOI: 10.7326/M18-1377
- TRIPOD+AI(配套报告规范): Collins GS, Moons KGM, Dhiman P, et al. TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ . 2024;385:e078378. DOI: 10.1136/bmj-2023-078378
- PROBAST 原始验证研究: Moons KGM, de Groot JAH, Bouwmeester W, et al. Critical appraisal and data extraction for systematic reviews of prediction modelling studies: the CHARMS checklist. PLoS Med . 2014;11(10):e1001744. DOI: 10.1371/journal.pmed.1001744
Settings
Required columns: Study, Outcome_Type, D1, D2, D3, D4, D5, D6
Risk Level Colors
ROBUST-RCT Risk of Bias Assessment
方法学依据 (Methodological Basis)
工具简介
ROBUST-RCT(Risk Of Bias instrument for Use in SysTematic reviews–Randomised Controlled Trials)是专为系统评价中 RCT 研究偏倚风险评估设计的工具,2025 年 3 月发表于 BMJ。该工具在保持方法学严谨性的同时追求 简洁性与可操作性的最优平衡 ,基于 16 场专家共识会议和 meta 流行病学证据开发,支持主观结局与客观结局的分类评估。
六个评估维度及设计依据
| 维度 | 英文 | 方法学依据 | 主/客观结局差异 |
|---|---|---|---|
| D1 | 随机序列产生 | 中等质量证据表明不充分的随机化会导致干预效果高估 | 无差异(客观结局同等重要) |
| D2 | 分配隐藏 | 中等质量证据表明分配隐藏不充分会导致效果高估 | 无差异 |
| D3 | 受试者盲法 | 患者报告结局中等质量证据支持高估;客观结局证据不确定 | 主观结局评分更严格 |
| D4 | 医护人员盲法 | 影响医疗行为,有理论依据但实证证据有限 | 主观结局评分更严格 |
| D5 | 结局评估者盲法 | 主观结局高确定性证据支持高估;客观结局证据不确定 | 主观结局显著更严格 |
| D6 | 缺失结局数据 | 低确定性证据表明大量缺失数据可能导致效果低估 | 无差异 |
四级评分体系
ROBUST-RCT 采用两步评估法: 第一步 评估方法学特征(肯定是/可能是/可能否/肯定否), 第二步 判断偏倚风险(Definitely Low / Probably Low / Probably High / Definitely High Risk)。Overall 由系统自动判定:任一 D1–D6 含 High → High Risk,否则 → Low Risk。
支撑文献
- ROBUST-RCT(主文献): Wang Y, Keitz S, Briel M, et al. Development of ROBUST-RCT: Risk Of Bias instrument for Use in SysTematic reviews–for Randomised Controlled Trials. BMJ . 2025;388:e081199. DOI: 10.1136/bmj-2024-081199
- RoB 2(Cochrane 工具,ROBUST-RCT 参照标准): Sterne JAC, Savović J, Page MJ, et al. RoB 2: a revised tool for assessing risk of bias in randomised trials. BMJ . 2019;366:l4898. DOI: 10.1136/bmj.l4898
- Meta 流行病学基础(盲法对效应估计的影响): Savović J, Jones HE, Altman DG, et al. Influence of reported study design characteristics on intervention effect estimates from randomized controlled trials. Ann Intern Med . 2012;157(6):429–438. DOI: 10.7326/0003-4819-157-6-201209180-00537
- 随机化与分配隐藏对效应估计的影响: Schulz KF, Chalmers I, Hayes RJ, Altman DG. Empirical evidence of bias: dimensions of methodological quality associated with estimates of treatment effects in controlled trials. JAMA . 1995;273(5):408–412. DOI: 10.1001/jama.1995.03520290060030
- Cochrane 系统评价手册(方法学基础): Higgins JPT, Thomas J, Chandler J, et al. Cochrane Handbook for Systematic Reviews of Interventions . Version 6.4. Cochrane, 2023. training.cochrane.org/handbook
设置
必需列:
author
、
year
、
AUC
95%CI 法需要:
X95CI_low
、
X95CI_up
Hanley-McNeil 法需要:
n_pos
(阳性例数)、
n_neg
(阴性例数)
可选:
Treatment
(亚组分析)
AUC 合并分析
Settings
Required:
author
,
year
,
event
(分子),
n
(分母)
Optional:
Subgroup
(亚组分析)
漏斗图 — 宽 6 × 高 6 英寸;森林图 — 宽 12 × 高 8 英寸
单个率 Meta-Analysis(Sen / Spe / ACC / NPV / PPV)
Settings
Required columns:
Group
,
Metric
,
Study_Value
,
Meta_Pooled
,
Meta_CI_Low
,
Meta_CI_High
,
Range_Min
,
Range_Max
Violin Plot — Se / Sp / AUC
研究设置
网页模式最多 20 篇,超过请使用 CSV 上传。
研究名称
导出图片
AI 辅助评分
★ = 得1分(蓝=Selection / 橙=Comparability / 绿=Outcome)
总分 ≥7★ → 高质量(低偏倚风险)
总分 4–6★ → 中等质量
总分 ≤3★ → 低质量(高偏倚风险)
NOS 条目评分录入
手动模式:为每篇研究的每个条目选择对应选项,结果自动更新。 上传模式:左侧上传 CSV 后结果自动显示。
NOS 评分结果
NOS 量表简介
Newcastle-Ottawa 量表(Newcastle-Ottawa Scale,NOS)由加拿大 Ottawa 大学与澳大利亚 Newcastle 大学联合开发, 是目前最广泛使用的观察性研究(队列研究与病例对照研究)质量评价工具之一, 已被 Cochrane 协作网和众多系统综述/Meta 分析指南推荐采用。
评分结构与质量分级
NOS 量表涵盖三大评价域,队列研究与病例对照研究均为最高 9 ★:
| 评价域 | 队列研究 | 病例对照研究 | 评价内容 |
|---|---|---|---|
| Selection(选择) | 最高 4 ★ | 最高 4 ★ | 研究人群代表性、暴露/病例定义与对照选择 |
| Comparability(可比性) | 最高 2 ★ | 最高 2 ★ | 是否控制最重要混杂因素及其他混杂 |
| Outcome / Exposure(结局/暴露) | 最高 3 ★ | 最高 3 ★ | 结局评估方法、随访充分性及完整性 |
质量分级标准(参考 Modesti 等,2016):
高质量(低偏倚风险)
:总分 ≥ 7 ★;
中等质量
:总分 4–6 ★;
低质量(高偏倚风险)
:总分 ≤ 3 ★。
注:部分文献采用 ≥ 6 ★ 为高质量的截断值,建议在方法学部分明确说明所采用的分级标准。
核心参考文献
-
量表原始出处(必引):
Wells GA, Shea B, O'Connell D, Peterson J, Welch V, Losos M, Tugwell P. The Newcastle-Ottawa Scale (NOS) for assessing the quality of nonrandomised studies in meta-analyses. Ottawa Hospital Research Institute; 2000. Available from: http://www.ohri.ca/programs/clinical_epidemiology/oxford.asp -
NOS 评分者间一致性验证:
Lo CK, Mertz D, Loeb M. Newcastle-Ottawa Scale: comparing reviewers' to authors' assessments. BMC Med Res Methodol. 2014;14:45. doi: 10.1186/1471-2288-14-45 -
NOS 方法学评述:
Stang A. Critical evaluation of the Newcastle-Ottawa scale for the assessment of the quality of nonrandomized studies in meta-analyses. Eur J Epidemiol. 2010;25(9):603–605. doi: 10.1007/s10654-010-9491-z -
NOS 优缺点综述:
Luchini C, Stubbs B, Solmi M, Veronese N. Assessing the quality of studies in meta-analyses: Advantages and limitations of the Newcastle Ottawa Scale. World J Meta-Anal. 2017;5(4):80–84. doi: 10.13105/wjma.v5.i4.80 -
质量分级截断值参考:
Modesti PA, Reboldi G, Cappuccio FP, et al. Panethnic Differences in Blood Pressure in Europe: A Systematic Review and Meta-Analysis. PLoS One. 2016;11(1):e0147601. doi: 10.1371/journal.pone.0147601
方法学描述模板(可直接用于论文)
We assessed the methodological quality of included observational studies using the Newcastle-Ottawa Scale (NOS) [Wells et al., 2000]. For cohort studies, the NOS evaluates selection (up to 4 stars), comparability (up to 2 stars), and outcome assessment (up to 3 stars), yielding a maximum score of 9 stars. For case-control studies, the domains are selection (up to 4 stars), comparability (up to 2 stars), and exposure assessment (up to 3 stars), also yielding a maximum of 9 stars. Studies scoring ≥7 stars were considered high quality (low risk of bias), 4–6 stars as moderate quality, and ≤3 stars as low quality (high risk of bias) [Modesti et al., 2016]. Two reviewers independently assessed study quality, and discrepancies were resolved by consensus.
研究设置
QUADAS-2 用于诊断准确性研究的偏倚风险和适用性关注评估。
网页模式最多 20 篇,超过请使用 CSV 上传。
研究名称
列名:
Study, PS_ROB, PS_APP, IT_ROB, IT_APP, RS_ROB, RS_APP, FT_ROB
取值:
Low / High / Unclear
下载 quadas2_template.csv
导出图片尺寸
尺寸用于 PDF/TIFF 导出;页面预览高度保持固定。
导出图片
AI 辅助评分
QUADAS-2 条目录入
手动模式:为每篇研究选择各域的偏倚风险 / 适用性关注;上传模式:左侧上传 CSV 后自动显示。
QUADAS-2 评估结果
研究设置
QUADAS-3 适用于诊断准确性研究的系统综述, 评估 4 个域的偏倚风险及 3 个域的适用性关注,并提供整体判断。
网页模式最多 20 篇,超过请使用 CSV 上传。
研究名称
列名:
Study, PA_ROB, PA_APP, IT_ROB, IT_APP, TC_ROB, TC_APP, AN_ROB
值:
Low / High / II
下载示例模板:
quadas3_template.csv
图形颜色
导出汇总图
导出交通灯图
AI 辅助评分
High / II / Low 颜色可在上方调整;图内图例和导出文件会同步更新。
QUADAS-3 条目录入
手动模式:为每篇研究的每个域选择偏倚风险 / 适用性关注判定,结果自动更新。 上传模式:左侧上传 CSV 后结果自动显示。
QUADAS-3 评估结果
QUADAS-3 量表简介
QUADAS-3(Quality Assessment of Diagnostic Accuracy Studies-3)是诊断准确性研究质量评估的最新国际标准工具, 由 Whiting 等人在 2026 年发布,是 QUADAS-2 的全面更新版。QUADAS-3 明确区分 偏倚风险(Risk of Bias) 与 适用性关注(Applicability Concerns) ,引入了 20 个信号问题(Signalling Questions),采用 5 级回答选项(Y/PY/PN/N/NI), 并新增正式的整体判断(Overall Judgment)环节。 已被 Cochrane 诊断试验准确性研究组及国际系统综述指南推荐采用。
评估域结构
| 评估域 | 信号问题数 | 适用性评估 | 主要关注点 |
|---|---|---|---|
| 受试者 (PA) | 4 题 | ✔ | 单门设计、前瞻性纳入、连续/随机抽样、代表性 |
| 指标检验 (IT) | 4 题 | ✔ | 规范操作、盲法判读、实践一致性、阈值预设 |
| 目标条件 (TC) | 8 题 | ✔ | 参考标准充分性、全员验证、统一方式、避免纳入偏倚、盲法、时间间隔 |
| 分析 (AN) | 4 题 | ✘ | 全员纳入分析、缺失数据处理、分析单位、统计方法适当性 |
注:QUADAS-3 域级判定为 Low / High / Insufficient Information (II)。 整体判断(Overall Judgment):若所有域均为 Low 则整体 Low;任一域为 High 则整体 High;其余为 II。
核心参考文献
-
QUADAS-3 原始出处(必引):
Whiting PF, Tomlinson E, Rutjes AWS, et al. QUADAS-3: A revised tool for the quality assessment of diagnostic test accuracy studies. Ann Intern Med. 2026. doi: 10.7326/ANNALS-25-02104 -
QUADAS-3 解释与阐述:
Davenport CF, Rutjes AWS, Mallett S, et al. QUADAS-3 explanation and elaboration: guidance for quality assessment of diagnostic test accuracy studies. Ann Intern Med. 2026. doi: 10.7326/ANNALS-25-04943 -
Cochrane 诊断试验方法学手册:
Deeks JJ, Bossuyt PM, Leeflang MM, Takwoingi Y (editors). Cochrane Handbook for Systematic Reviews of Diagnostic Test Accuracy. Version 2.0. 2023. doi: 10.1002/9781119756194 -
STARD 报告规范:
Bossuyt PM, Reitsma JB, Bruns DE, et al. STARD 2015: An updated list of essential items for reporting diagnostic accuracy studies. BMJ. 2015;351:h5527. doi: 10.1136/bmj.h5527
方法学描述模板(可直接用于论文)
We assessed the methodological quality of included diagnostic accuracy studies using the QUADAS-3 tool (Whiting et al., 2026). QUADAS-3 evaluates four key domains: participants, index test, target condition, and analysis. For each domain, we judged the risk of bias as low, high, or insufficient information based on pre-specified signalling questions answered as yes (Y), probably yes (PY), probably no (PN), no (N), or no information (NI). Applicability concerns were additionally assessed for the first three domains (participants, index test, target condition). An overall judgment of risk of bias and applicability was derived across all domains for each study. Two reviewers independently assessed study quality; discrepancies were resolved through discussion or consultation with a third reviewer. Results are presented as a traffic-light summary plot showing the proportion of studies at each level of bias risk per domain.
贝叶斯网状Meta分析 — 统一模块(连续型 / 二分类 / 预合并)
支持三种数据格式:
连续型:
study, treatment, sampleSize, mean, std.dev
— SMD(Hedges' g)或 MD
二分类:
studlab, treat1, treat2, event1, n1, event2, n2
— OR / RR / RD
预合并型:
studlab, treat1, treat2, effect, ci_lower, ci_upper
— HR / OR / RR(已发表效应量)
下载示例模板
分析设置
治疗措施标签(可编辑)
MCMC 参数设置
数据预览
图形设置
节点颜色渐变
网络关系图
节点代表各治疗措施,节点大小正比于该治疗的总样本量(预合并数据则为均等大小)。
连线粗细正比于直接比较的研究数量;颜色仅用于区分不同治疗节点。
孤立节点或仅有一条连线的治疗排名主要依赖间接证据;存在闭合回路时应进行节点拆分。
DIC 比较 — 全局不一致性检验
DIC 比较一致性模型与UME不一致性模型的拟合优度。
结果解读
|ΔDIC| < 5:无显著全局不一致性,推荐使用一致性模型。
|ΔDIC| 5–10:轻度不一致性信号,建议结合节点拆分定位。
|ΔDIC| ≥ 10:存在显著全局不一致性,需批判性解释结果。
注意:研究数量较少时(<10项)统计效能有限。
森林图展示所有治疗相对于参考治疗的后验效应量估计(点估计及 95% 可信区间)。
对于连续型(SMD/MD),竖线为零效应;对于比例比(OR/RR/HR),竖线为 1(使用对数尺度);RD 竖线为 0。
粗体数值(联赛表):95% CrI 不包含无效值,具有统计学意义。
ROPE(仅SMD):灰色竖带为临床等效区间,CrI 完全在 ROPE 内提示临床等效。
SUCRA(排序概率曲线下面积)综合刻画每种治疗在所有排名位次上的后验概率,数值越高排名越靠前。
SUCRA 接近 1(100%):该治疗很可能优于所有其他治疗;接近 0:很可能劣于所有其他治疗。
SUCRA 仅反映排名,不代表效应量大小,需结合森林图判断临床意义。
排名方向已根据「数据录入」页面设置调整(越大越好 / 越小越好)。
以颜色深浅直观展示每种治疗在不同排名位次上的后验概率分布。
横轴为排名位次(第1名=最优),纵轴为各治疗;单元格颜色代表排在该位次的后验概率。
颜色集中在左列(第1、2名)表示排名靠前;分散则表示排名不确定性大。
配色
渐变颜色(低→中→高 SUCRA)
累积概率曲线展示每种治疗在各排名位次上的后验概率。
曲线越靠上表示排名越靠前的概率越大(SUCRA = 曲线下面积)。
治疗按 SUCRA 由高到低着色(可在左侧面板调整颜色)。
配色
曲线颜色范围
Gelman-Rubin PSRF 收敛诊断
< 1.05:收敛良好
1.05–1.10:边界状态
> 1.10:未收敛,建议增加迭代次数
PSRF < 1.05:所有链已充分混合,后验估计可靠;
1.05–1.10:处于临界状态,建议增大迭代次数;
> 1.10:链间差异过大,未收敛,结果不可信。
迹图:各链应呈现良好混合性(毛毛虫形态);
密度图:各链后验分布曲线应高度重叠。
对每对存在直接比较的治疗,分别估计直接证据与间接证据的效应量,检验二者是否一致。
P-value > 0.05:直接与间接证据一致;P < 0.05:存在局部不一致性。
节点拆分仅适用于含闭合回路的比较对,纯直接证据对无法进行此检验。
颜色设置
Egger 检验(发表偏倚)
对每项研究的效应量进行比较调整(减去该对比较的网络汇总估计),消除不同比较基准的差异。
横轴为调整后效应量,纵轴为标准误(越大代表样本量越小);漏斗边界为 ±1.96 × SE。
图形对称提示无明显发表偏倚;不对称(尤其漏斗底部)提示小研究效应或发表偏倚。
建议同时参考右侧 Egger 检验 P 值,至少需要 10 项研究才能可靠评估。
Meta 回归分析(贝叶斯 NMA)
Meta 回归
通过引入研究水平协变量(如平均年龄、发表年份等),探索协变量对治疗效应的调节作用,解释异质性来源。
协变量文件格式:
需包含
study
列(与主数据一致)及协变量列;
连续型
直接填写数值;
分类型(二分类)
用 0/1 编码;
多分类
用 0/1/2/3 编码。
关键结果:
重点关注回归系数 β 及其 95% 可信区间(CrI);CrI 不包含 0 则协变量对治疗效应有统计学显著调节作用。
协变量设置
协变量数据预览
Meta 回归结果
汇总网络中每对直接比较的异质性统计量(τ²、I²),每行代表一对直接比较。
τ²:研究间方差后验估计;I² 参考:<25% 低度,25–75% 中度,>75% 高度。
高异质性不等于 NMA 不可行,但会增大 CrI 宽度,需在报告中充分说明。
异质性(Heterogeneity)与不一致性(Inconsistency)概念不同:前者为研究间真实效应差异,后者为直接与间接证据矛盾。
SoF 热图(GRADE) — 数据录入
功能:
将 NMA 汇总结果可视化为多结局 Summary of Findings 热图,支持同一张图混合 OR/RR/RD/MD/SMD。
颜色含义:
绿色
= 获益;
红色
= 有害;
黄色
= 无显著差异;斜纹 = 低/极低证据质量。
CSV 必需列:
Intervention, Outcome, Effect, Lower, Upper, EffectType, Direction
EffectType:
每行填写效应量类型,可选值:
OR
、
RR
、
RD
、
MD
、
SMD
。
Direction:
仅 MD/SMD 行需要填写,可选值:
higher_better
(数值越高越好)或
lower_better
(数值越低越好);OR/RR/RD 行留空即可。
判断规则:
OR/RR — 95%CI 是否跨越 1;RD/MD/SMD — 95%CI 是否跨越 0。
下载 SoF 模板
SoF 热图(Summary of Findings)
频率学网状Meta分析 — 统一模块(连续型 / 二分类 / 预合并型)
方法:
netmeta 频率学框架(随机/固定效应)。
连续型:
SMD/MD,臂级数据,需包含
study, treatment, sampleSize, mean, std.dev
。
二分类:
OR/RR/RD,对比级数据,需包含
studlab, treat1, treat2, event1, n1, event2, n2
。
预合并型:
HR/OR/RR,仅有效应量+CI,需包含
studlab, treat1, treat2, effect, ci_lower, ci_upper
。
下载模板
分析设置
治疗措施标签(可编辑)
数据预览
图形设置
节点颜色渐变
下载图片
网络关系图
节点(圆圈)代表纳入网络的各治疗措施,节点大小正比于该治疗参与研究的总患者数(连续型)或研究频次(预合并型)。
连线(边)代表两种治疗之间存在直接比较研究,连线粗细正比于直接对比的研究数量;勾选「显示连线上的研究数量」可进一步量化每对比较的证据来源。
颜色仅用于区分不同治疗节点,无额外统计含义。
🔍 解读要点
① 孤立节点或仅有一条连线的治疗,排名结果主要来自间接证据,不确定性较大,需谨慎解读;
② 网络越密集(闭合回路越多),直接与间接证据的相互验证能力越强,NMA 结果更为可靠;
③ 存在闭合回路时,应结合节点拆分检验局部一致性;
④ 若某治疗仅与参考治疗存在直接连线,其效应量估计主要来自间接证据,置信区间往往较宽。
图形设置
参考治疗在【数据录入】页设置。
下载图片
森林图(相对于参考治疗)
本图展示所有治疗措施相对于参考治疗的网状 Meta 分析效应量估计,横轴为效应量大小,竖虚线为无效线(SMD/MD/RD = 0;OR/RR/HR = 1)。
点估计(圆点)为随机效应模型汇总效应,水平线为 95% 置信区间(CI);
勾选「同时显示固定效应结果」可对比两种模型;勾选「显示预测区间」可呈现效应量在未来新研究中的预测范围(通常比 CI 更宽)。
🔍 结果解读
① 95% CI 完全不含无效线:效应有统计学意义;
② SMD 效应量参考:|SMD| ≈ 0.2 为小效应,≈ 0.5 为中等效应,≈ 0.8 为大效应;
③ 预测区间比 CI 更宽,体现了效应在不同研究情境下的异质性;
④ 直接比较研究较少的治疗,CI 通常更宽,效应估计主要来自间接证据,需谨慎解读。
排名设置
P-Score 为频率学排名指标,范围 0–1,越高代表治疗效果越优。
排名方向在【数据录入】页设置。
下载图片
P-Score 排名图
P-Score(频率学排名概率得分)是 SUCRA 的频率学对应指标,取值范围 0–1,综合刻画每种治疗优于网络中其他所有治疗的平均概率。
条形高度代表 P-Score 值,越高表示排名越靠前;条内白色数字为排名位次;下方表格列出精确数值,可下载。
🔍 结果解读
① P-Score 接近 1:该治疗综合排名最优;接近 0 则排名最末;
② P-Score 仅反映排名顺序,不代表效应量大小——P-Score 相差较大时,仍需结合森林图判断临床实际意义;
③ 排名方向(越小越好 / 越大越好)在【数据录入】页设置,不同方向将改变排名结果;
④ 当多个治疗 P-Score 相近(差距 < 0.05)时,需谨慎过度解读排名差异;可参考 P-Score 热图了解完整的排名概率分布。
P-Score 热图以颜色深浅直观展示每种治疗在不同排名位次上的模拟概率分布(基于 500 次模拟,颜色可自定义)。
横轴为排名位次(第1名=最优),纵轴为各治疗措施,行顺序按 P-Score 由高到低排列。
🔍 结果解读
① 颜色集中在左列:该治疗排名靠前的概率高;② 颜色集中在右列:综合效果欠佳;
③ 颜色分散:排名不确定性大;④ 排名方向(越小越好 / 越大越好)在【数据录入】页设置。
配色
渐变颜色(低→中→高 P-Score)
颜色设置
联赛表(Pairwise Comparisons)
检验说明与配色
全局检验:
Design-by-treatment interaction test,p > 0.05 表示全局一致性良好。
Net Heat Plot:
单元格颜色反映直接与间接证据的不一致程度,颜色越深表示该比较对不一致性贡献越大。
🎨 热图配色(低→中→高)
下载图片
全局不一致性热图(Net Heat Plot)
Net Heat Plot 可视化网络中每对直接比较对全局不一致性的贡献程度。矩阵的行与列均代表具体的比较对;单元格颜色越深(红),表示该比较对与网络整体不一致性的关联越强,是不一致性的主要来源。
左侧面板同步显示 Design-by-Treatment 不一致性检验的全局 Q 统计量和 p 值。
🔍 结果解读
① 全局检验 p > 0.10:未发现显著全局不一致性,NMA 一致性假设基本成立;
② 全局检验 p < 0.05:存在显著全局不一致性,应进一步通过节点拆分定位来源;
③ 热图中深色格对应的比较对是不一致性的主要来源,可考虑敏感性分析(如剔除相关研究);
④ 全局检验与节点拆分(局部检验)互为补充:全局检验灵敏度高,节点拆分定位更精确。
设置
节点拆分(Node-Splitting)比较直接证据与间接证据的一致性。
p < 0.05 表示该比较存在显著不一致。
配色设置
下载图片
节点拆分森林图
节点拆分(Node-Splitting)将每个闭合回路上某一比较对的直接证据与间接证据分离,分别估计效应量并检验两者是否一致。
图中每行代表一对可拆分的比较,同时呈现直接估计、间接估计及 NMA 合并估计(含 95% CI);下方表格列出各对比较的不一致性检验 p 值。
🔍 结果解读
① 直接 vs 间接 p < 0.05:该比较对的直接与间接证据存在显著不一致,需深入审查(如人群差异、剂量不同等);
② 直接与间接 CI 高度重叠:一致性良好,对应 NMA 合并估计可信;
③ 若多对比较均出现不一致,提示可能存在系统性偏倚,建议在讨论部分阐明局限性;
④ 节点拆分仅适用于有闭合回路的比较对;纯间接比较(无直接证据)的配对不出现在本图中。
设置
比较校正漏斗图(Comparison-adjusted funnel plot) 检测发表偏倚。Egger 检验 p < 0.05 提示可能存在发表偏倚。
下载图片
比较校正漏斗图(Egger 检验)
比较校正漏斗图(Comparison-Adjusted Funnel Plot)在消除不同比较对基线效应差异后,评估网状 Meta 分析中的发表偏倚和小样本效应。
横轴为经比较校正的效应量,纵轴为标准误(标准误越小代表研究精度越高/样本量越大);不同颜色代表不同比较对。若研究数达到设定阈值,左侧面板自动计算 Egger 线性回归检验结果。
🔍 结果解读
① 漏斗图对称(各点均匀分布于中心轴两侧):无明显发表偏倚或小样本效应;
② 漏斗图不对称(一侧研究点偏多或偏少):可能存在发表偏倚、小样本效应或真实异质性,需结合 Egger 检验综合判断;
③ Egger 检验 p < 0.05:统计学上存在显著小样本效应,解读 NMA 结果时应注意潜在偏倚;
④ 比较校正漏斗图要求每对比较至少有 3 条研究,研究数较少时检验效能有限,阴性结果不能完全排除偏倚。
Meta 回归分析(频率学 NMA — 统一模块)
Meta 回归
通过引入研究水平协变量(如平均年龄、发表年份等),
探索协变量对治疗效应的调节作用,解释异质性来源。
注意:
频率学 NMA 不支持内置 Meta 回归,此处借用贝叶斯 gemtc 框架进行分析(需安装 gemtc 和 rjags)。
协变量文件格式:
需包含
study
列(连续型与主数据 study 一致;二分类/预合并型与 studlab 一致)及协变量列;
连续型
协变量直接填写数值;
分类型
请用 0/1 编码;
多分类
请用 0/1/2/3 编码。
关键结果:
重点关注回归系数 β 及其 95% 可信区间(CrI);
若 CrI 不包含 0,则协变量对治疗效应有统计学显著调节作用。
协变量设置
协变量数据预览
Meta 回归结果
SoF 热图(GRADE) — 数据录入
功能:
将 NMA 汇总结果可视化为多结局 Summary of Findings 热图,支持同一张图混合 OR/RR/RD/MD/SMD。
颜色含义:
绿色
= 获益;
红色
= 有害;
黄色
= 无显著差异;斜纹 = 低/极低证据质量。
CSV 必需列:
Intervention, Outcome, Effect, Lower, Upper, EffectType, Direction
EffectType:
每行填写效应量类型,可选值:
OR
、
RR
、
RD
、
MD
、
SMD
。
Direction:
仅 MD/SMD 行需要填写,可选值:
higher_better
(数值越高越好)或
lower_better
(数值越低越好);OR/RR/RD 行留空即可。
判断规则:
OR/RR — 95%CI 是否跨越 1;RD/MD/SMD — 95%CI 是否跨越 0。
下载 SoF 模板
SoF 热图(Summary of Findings)
数据上传与设置
推荐:REML(Cochrane 手册推荐,偏差最小);研究数较少(<5)时可选 DL 或 PM
适用条件:研究数较少或异质性较大时建议勾选,可提供更保守准确的置信区间;
研究数极少(<5)时效果有限,需谨慎解读
下载示例数据
数据预览
森林图设置
森林图
方块为各研究效应量,大小正比于权重; 菱形为合并效应估计。 虚线为合并效应线, 实线为无效线。 I² 反映研究间异质性程度。
漏斗图 (Funnel Plot)
等高线增强漏斗图 (Contour-enhanced Funnel Plot)
等高线增强漏斗图叠加统计显著性区域(P < 0.01, P < 0.05, P < 0.10)。
判断逻辑:
若缺失研究主要落在非显著区域(无底色) → 提示发表偏倚。
若缺失研究落在显著区域(有底色) → 提示其他原因(如研究质量差异)。
注:等高线独立于合并效应值,与伪 95% CI 不同。应与剪补法联合使用。
Egger 线性回归检验结果
Egger 线性回归检验评估发表偏倚。P < 0.1 提示可能存在发表偏倚。 研究数 < 10 时检验效能不足,建议结合剪补法。
Begg 秩相关检验结果
Begg 秩相关检验基于效应量与其方差的秩相关(Kendall's tau)评估发表偏倚。
与 Egger 检验互补:
Egger 基于线性回归,对连续型结局更敏感,但受异质性影响较大。
Begg 基于秩次,更稳健但检验效能较低。
两者均建议在纳入 ≥ 10 项研究时使用。
剪补后森林图
剪补后漏斗图
剪补法摘要
剪补法(Trim-and-Fill)通过迭代填充缺失研究来校正发表偏倚。 若填充研究数为 0,说明漏斗图不对称程度不显著。
留一法(Leave-One-Out):依次剔除每项研究后重新计算合并效应量。 若结果在剔除某研究后发生显著变化,提示该研究对合并结果影响较大。
Meta 回归结果
Meta 回归探索效应量与协变量之间的关联。选择连续型或分类协变量。 R² 反映协变量对异质性的解释程度。需至少 10 项研究以保证检验效能。
气泡图 (Bubble Plot)
气泡图是 Meta 回归的可视化工具。X 轴为协变量值,Y 轴为效应量,气泡大小正比于研究精度(1/方差)。回归线反映协变量对效应量的调节趋势。
解读注意:
1. Meta 回归得出的关联是观察性的(非因果关系),弱于随机对照试验的因果推断。
2. 使用研究层面的患者特征均值(如平均年龄)作为协变量时,存在生态学谬误风险。
3. 应预先设定待检验的协变量,避免数据挖掘导致假阳性。
仅在选择了 Meta 回归协变量并运行分析后可用。
Galbraith 径向图 (Radial Plot)
Galbraith 径向图(radial plot)用于可视化诊断研究间异质性。
X 轴 = 精度(1/SE),Y 轴 = 标准化效应量 z = 效应量/SE。
图形构造:
中心参考线:过原点、斜率 = 固定效应合并效应量的直线。
±2 平行带:参考线上下各平移 2 个单位(即 z ± 2),对应「研究效应量 = 合并效应量 ± 2·SE」的边界(约 95% 预期范围)。
解读方法:
同质研究的点应围绕参考线等方差散布,落在 ±2 带外的研究值得进一步审视(但最终判断异质性仍需结合 Q 检验与 I² 统计量)。
精度高的研究(大样本)分布在右侧,1/SE² 即为固定效应模型中该研究的权重;精度低的研究聚集在原点附近,不易突破 ±2 带。
L'Abbé 拉贝图 (L'Abbé Plot)
每个圆圈代表一项研究(圆圈越大 = 样本量越大),图上标注了研究名称。
X 轴 = 对照组的事件发生率,Y 轴 = 试验组的事件发生率。
怎么看这张图:
1. 实线对角线(45°)= 两组事件率相等,即治疗完全无效。
圆圈在对角线下方 → 试验组事件率更低(治疗有保护效果)。
圆圈在对角线上方 → 试验组事件率更高(治疗可能有害)。
2. 虚线 = 所有研究合并后的总体效应线。
大部分圆圈应该聚集在虚线附近。
3. 找离群研究:远离虚线的圆圈就是导致异质性的"问题研究"。
看它偏向哪个方向可以判断原因:
- 水平偏离大 → 该研究的对照组事件率异常(可能是对照组人群不同)
- 垂直偏离大 → 该研究的试验组事件率异常(可能是干预实施差异)
注意:仅适用于二分类数据。发现离群研究后应分析其临床特征,不应仅通过排除来解决异质性。
累积 Meta 分析 (Cumulative Meta-Analysis)
累积 Meta 分析按指定变量(通常为发表年份)逐步纳入研究,展示合并效应量随研究累积的时间演变趋势。
用途:
1. 判断合并效应是否随时间趋于稳定(证据充分性)。
2. 识别关键转折研究(哪项研究的加入使结论发生改变)。
3. 评估早期研究是否存在过度乐观偏倚。
排序变量默认按研究标签中的年份排序。如需按其他变量排序,可在数据中添加相应列。
数据上传与设置
数据预览
森林图设置
森林图
方块为各研究效应量,大小正比于权重; 菱形为合并效应估计。 虚线为合并效应线, 实线为无效线。 I² 反映研究间异质性程度。
漏斗图 (Funnel Plot)
等高线增强漏斗图 (Contour-enhanced Funnel Plot)
等高线增强漏斗图叠加统计显著性区域(P < 0.01, P < 0.05, P < 0.10)。
判断逻辑:
若缺失研究主要落在非显著区域(无底色) → 提示发表偏倚。
若缺失研究落在显著区域(有底色) → 提示其他原因(如研究质量差异)。
Egger 线性回归检验结果
Egger 线性回归检验评估发表偏倚。P < 0.1 提示可能存在发表偏倚。 研究数 < 10 时检验效能不足,建议结合剪补法。
Begg 秩相关检验结果
Begg 秩相关检验基于效应量与其方差的秩相关(Kendall's tau)评估发表偏倚。
Egger 基于线性回归,对连续型结局更敏感,但受异质性影响较大。
Begg 基于秩次,更稳健但检验效能较低。两者均建议在纳入 ≥ 10 项研究时使用。
剪补后森林图
剪补后漏斗图
剪补法摘要
剪补法(Trim-and-Fill)通过迭代填充缺失研究来校正发表偏倚。 若填充研究数为 0,说明漏斗图不对称程度不显著。
留一法(Leave-One-Out):依次剔除每项研究后重新计算合并效应量。 若结果在剔除某研究后发生显著变化,提示该研究对合并结果影响较大。
Meta 回归结果
Meta 回归探索效应量与协变量之间的关联。选择连续型或分类协变量。 R² 反映协变量对异质性的解释程度。需至少 10 项研究以保证检验效能。
气泡图 (Bubble Plot)
气泡图是 Meta 回归的可视化工具。X 轴为协变量值,Y 轴为效应量,气泡大小正比于研究精度(1/方差)。回归线反映协变量对效应量的调节趋势。
仅在选择了 Meta 回归协变量并运行分析后可用。
Galbraith 径向图 (Radial Plot)
Galbraith 径向图(radial plot)用于可视化诊断研究间异质性。
X 轴 = 精度(1/SE),Y 轴 = 标准化效应量 z = 效应量/SE。
图形构造:
中心参考线:过原点、斜率 = 固定效应合并效应量的直线。
±2 平行带:参考线上下各平移 2 个单位(即 z ± 2),对应「研究效应量 = 合并效应量 ± 2·SE」的边界(约 95% 预期范围)。
解读方法:
同质研究的点应围绕参考线等方差散布,落在 ±2 带外的研究值得进一步审视(但最终判断异质性仍需结合 Q 检验与 I² 统计量)。
精度高的研究(大样本)分布在右侧,精度低的研究聚集在原点附近。
累积 Meta 分析 (Cumulative Meta-Analysis)
累积 Meta 分析按指定变量(通常为发表年份)逐步纳入研究,展示合并效应量随研究累积的时间演变趋势。
排序变量默认按研究标签中的年份排序。如需按其他变量排序,可在数据中添加相应列。
数据设置
预合并模式:必需列 —
study(研究 ID), esid(效应量 ID,每行唯一), yi(效应量), vi(方差)或 sei(标准误)。原始数据模式:必需列因数据类型而异,需包含
study 和 esid 列。二分类:
ai, bi, ci, di;连续型: m1i, sd1i, n1i, m2i, sd2i, n2i;相关系数: ri, ni;单个率: xi, ni。可选列: 任意调节变量(分类型/连续型均可)。
数据预览
三水平 Meta 分析森林图
三水平森林图展示所有效应量,按研究分组排列。每个方块代表一个效应量,大小与权重成比例。底部钻石为合并效应量估计及 95% CI。
分组模式下,同一研究的多个效应量被聚合在一起展示,便于识别研究内变异。
方差分量与异质性分解
σ²₂ (Level 2): 研究内异质性 — 同一研究不同效应量之间的变异。
σ²₃ (Level 3): 研究间异质性 — 不同研究之间的变异。
I²(2): 总变异中归因于研究内异质性的比例。
I²(3): 总变异中归因于研究间异质性的比例。
ICC: 组内相关系数 = σ²₃/(σ²₂+σ²₃),反映效应量在研究间的聚集程度。
似然比检验 (LRT): 将三水平模型与约束模型对比,检验各层方差分量是否显著不为零。
Profile Likelihood — σ²₂ (研究内)
Profile Likelihood — σ²₃ (研究间)
离群值检测 (|z| > 3.29)
标准化残差绝对值 > 3.29 的效应量被标记为潜在离群值(α ≈ 0.001)。离群值可能对合并效应量产生不成比例的影响,建议检查原始数据。
漏斗图 (Funnel Plot)
漏斗图用于目视检查发表偏倚。对称分布提示无偏倚。
注意:三水平模型包含依赖效应量,传统漏斗图和 Egger 检验的假设可能不完全满足。结果应谨慎解读 (Pustejovsky & Tipton 2021)。
Egger 型回归检验
调节变量设置
分类变量自动生成哑变量,连续变量自动中心化。
使用 Omnibus F 检验评估调节变量的整体显著性 (Assink & Wibbelink 2016)。
调节因子分析结果
研究层留一法 (Leave-One-Study-Out)
逐一剔除每个研究(包含其全部效应量),重新拟合三水平模型。检查合并效应量是否因某个研究的纳入而发生实质性改变。
效应量层留一法 (Leave-One-ES-Out)
稳健方差估计 (Robust Variance Estimation)
稳健方差估计 (RVE) 使用 clubSandwich 包的 CR2 估计量,即使工作模型(三水平结构)设定不完全准确,标准误仍然渐近无偏。
对比标准 rma.mv 推断与 RVE 稳健推断:若结果一致,说明模型设定可靠;若差异较大,提示模型可能存在错误设定。
三水平 Meta 分析方法学说明
一、何时需要三水平 Meta 分析?
传统两水平 Meta 分析假设各效应量独立。但在实际中,以下情况导致效应量依赖:
- 同一研究报告多个结局指标(如认知功能、行为评分、生活质量)
- 同一研究报告多个时间点的效应量
- 同一研究比较多个处理组与同一对照组
- 同一研究在多个亚人群(如不同年龄段)中报告结果
- 跨文化 Meta 分析中,多个研究嵌套于同一文化/国家
忽略依赖性会导致标准误低估、I 类错误膨胀 (Cheung 2014)。传统处理方式(取平均、仅选一个效应量)会丢失信息。三水平模型在保留所有效应量的同时正确建模依赖结构。
二、三水平模型
模型将变异分解为三个层次 (Van den Noortgate et al. 2013, 2014):
yij = β₀ + uj(3) + uij(2) + eij Level 1: eij ~ N(0, vij) 已知抽样方差(取决于样本量) Level 2: uij(2) ~ N(0, σ²₂) 研究内异质性(同一研究不同效应量间的变异) Level 3: uj(3) ~ N(0, σ²₃) 研究间异质性(不同研究间的变异) 其中 i = 效应量索引, j = 研究/聚类索引
三、异质性分解指标 (Cheung 2014)
I²(2) = σ²₂ / (σ²₂ + σ²₃ + s²typ) 研究内异质性占比 I²(3) = σ²₃ / (σ²₂ + σ²₃ + s²typ) 研究间异质性占比 ICC = σ²₃ / (σ²₂ + σ²₃) 组内相关系数 s²typ = (k - p) / tr(P) 典型抽样方差
四、软件实现
本模块使用 metafor R 包 (Viechtbauer 2010) 的 rma.mv() 函数:
res <- rma.mv(yi, vi,
random = list(~1|study, ~1|esid),
tdist = TRUE, # Knapp-Hartung 调整
method = "REML",
data = dat)Knapp-Hartung 调整 (tdist=TRUE) 使用 t 分布替代正态分布,在研究数较少时提供更保守的推断 (Assink & Wibbelink 2016)。
五、适用场景推荐
| 场景 | 推荐方法 | 说明 |
|---|---|---|
| 每个研究仅 1 个效应量 | 传统两水平 Meta | 三水平模型退化为两水平 |
| 每个研究多个效应量(≥2) | 三水平 Meta | 正确建模依赖结构 |
| 效应量间协方差已知 | 多变量 Meta | 直接利用已知协方差 |
| 效应量间协方差未知 | 三水平 Meta | 无需估计协方差 (Van den Noortgate 2013) |
| 研究数极少(<5) | 谨慎使用 | 方差分量估计不稳定 |
六、参考文献
- Cheung MW-L. Modeling dependent effect sizes with three-level meta-analyses: a structural equation modeling approach. Psychol Methods. 2014;19(2):211-229.
- Assink M, Wibbelink CJM. Fitting three-level meta-analytic models in R: a step-by-step tutorial. Quant Methods Psychol. 2016;12(3):154-174.
- Van den Noortgate W, et al. Three-level meta-analysis of dependent effect sizes. Behav Res Methods. 2013;45(2):576-594.
- Van den Noortgate W, et al. Meta-analysis of multiple outcomes: a multilevel approach. Behav Res Methods. 2014;47(4):1274-1294.
- Viechtbauer W. Conducting meta-analyses in R with the metafor package. J Stat Softw. 2010;36(3):1-48.
- Pustejovsky JE, Tipton E. Meta-analysis with robust variance estimation: expanding the range of working models. Prev Sci. 2022;23(3):425-438.
- Greenland S, Longnecker MP. Methods for trend estimation from summarized dose-response data. Am J Epidemiol. 1992;135(11):1301-1309.
- Konstantopoulos S. Fixed effects and variance components estimation in three-level meta-analysis. Res Synth Methods. 2011;2(1):61-76.
数据上传
下载示例数据
累积发病率 (CI) — 10篇 发病率/人时 (IR) — 5篇 预合并 logrr+se — 5篇study(研究名)、dose(剂量)、cases(事件数)、n(总人数)可选列:
logrr + se(已有效应量时提供,否则自动计算)注意:每个研究须包含参考剂量行(通常 dose = 0)
分析设置
● 线性:剂量越高风险越大(或越小),适合初步探索
● 二次多项式:允许 U 型/倒 U 型关系
● RCS 样条:最灵活,可发现阈值、J 型等复杂趋势
数据预览
剂量-反应曲线 (Dose-Response Curve)
方法学依据: Greenland & Longnecker (1992); Orsini et al. (2012); Crippa & Orsini (2016)
模型摘要
参数设置
结局数量
上传 ROBUST-RCT 文件(可选)
CSV 格式,列名: Study, Outcome_Type, D1, D2, D3, D4, D5, D6, Overall
从质量评价导入 ROB
自动导入 NOS 或 QUADAS-3 模块的偏倚风险评伋(请先完成评估)
ROB 模板下载
结局定义与评估
D1: 随机化过程 | D2: 基线失衡 | D3: 结局数据缺失
D4: 结局测量(盲法) | D5: 选择性报告 | D6: 其他偏倚
颜色: 🟢 肯定低风险 | 🟡 可能低风险 | 🟠 可能高风险 | 🔴 肯定高风险
⊕⊕⊕⊕ High(高): 对效应估计值非常有信心,真实效应接近估计值。
⊕⊕⊕⊖ Moderate(中): 对估计值有中等信心,真实效应可能接近但也可能有较大差异。
⊕⊕⊖⊖ Low(低): 信心有限,真实效应可能与估计值有较大差异。
⊕⊖⊖⊖ Very Low(极低): 信心极低,真实效应很可能与估计值有很大差异。
起始等级: RCT = High; NRSI = Low
证据摘要表 (SoF)
参考文献: Schünemann et al. BMJ GRADE series 2025; GRADE Working Group 2013.
数据上传与设置
必须列:study, TP, FP, FN, TN
可选列:任意额外列将作为亚组/协变量选项
下载示例数据
每行代表一项研究的 2×2 诊断数据:
TP(真阳性)/ FP(假阳性)
FN(假阴性)/ TN(真阴性)
数据预览
配色设置(森林图)
SROC 调色设置
总体 SROC 曲线
📐 预测区域的含义(Cochrane DTA Handbook Chapter 11.5):
虚线椭圆为 95% 预测区域:未来新研究的结果预计有 95% 的概率落在此范围内。 预测区域越大,说明研究间异质性越大。如果预测区域与置信区域差距很大, 则提示存在较大的异质性,应探索可能的异质性来源(如亚组分析、Meta 回归)。
在 DTA Meta 分析中,预测区域比 I² 更能准确反映异质性程度。
阈值效应检验
拟合优度检验
⚠️ 注意:Cochrane DTA Handbook (Chapter 11.5) 指出,I² 在诊断准确性 Meta 分析中不够可靠,建议优先参考 SROC 图中的预测区域来判断异质性大小。
ROC 平面散点图(阈值效应视觉评估)
若各点沿反对角线(左上到右下)分布,提示不同研究使用了不同阈值;
黄色区域为 95% 预测区域。结合上方 Spearman 检验综合判断。
Deeks' 漏斗图(发表偏倚检验)
以 log(DOR) 对 1/√ESS(有效样本量倒数的平方根)作加权线性回归, 检验斜率是否显著不为 0(p < 0.10 提示可能存在发表偏倚)。 这是诊断准确性研究推荐的发表偏倚检验方法;Egger's/Begg's 在诊断研究中易产生假阳性,不推荐。
📚 参考文献:
1. Deeks JJ, Macaskill P, Irwig L. The performance of tests of publication bias and other sample size effects in systematic reviews of diagnostic test accuracy was assessed. J Clin Epidemiol. 2005;58(9):882-893.
2. Macaskill P, Gatsonis C, Deeks JJ, et al. Chapter 10: Analysing and Presenting Results. In: Cochrane Handbook for Systematic Reviews of Diagnostic Test Accuracy, Version 1.0. The Cochrane Collaboration, 2010.
3. Song F, Khan KS, Dinnes J, Sutton AJ. Asymmetric funnel plots and publication bias in meta-analyses of diagnostic accuracy. Int J Epidemiol. 2002;31(1):88-95.
Deeks' 检验结果
Summary of Findings (SoF) 表格
标准化频数表(每 1000 人)
不同患病率下的 PPV / NPV
似然比 (LR) 临床解读
LR+: >10 强阳性证据 | 5–10 中等 | 2–5 弱阳性
LR−: <0.1 强阴性证据 | 0.1–0.2 中等 | 0.2–0.5 弱阴性
LR 将诊断准确性与临床决策直接连接:先验概率 × LR → 后验概率。
方法学依据 (Methodological Basis)
双变量模型 (Bivariate Model)
双变量模型由 Reitsma 等人(2005)提出,是当前诊断准确性系统评价中最主流的统计框架之一。 该模型通过 联合建模 logit-transformed 灵敏度和特异度 , 同时估计两者的均值、方差及协方差,从而保留了灵敏度与特异度之间的内在负相关(阈值效应)。
具体而言,设第 i 个研究的真阳性率为 Se i 、假阳性率为 FPR i ,模型将 (logit(Se i ), logit(FPR i )) 视为来自一个 二维正态分布 的随机效应:
其中 μ = (μSe, μFPR),Σ 为 2×2 协方差矩阵
合并灵敏度和合并特异度分别为 logit -1 (μ Se ) 和 1 − logit -1 (μ FPR )。 该模型的优势在于:(1) 无需假设研究间存在唯一阈值;(2) 可自然地纳入协变量进行 meta 回归; (3) 与 HSROC 模型在特定参数化下数学等价。
HSROC 模型 (Hierarchical Summary ROC)
HSROC 模型由 Rutter 和 Gatsonis(2001)提出,是对经典 Moses-Littenberg SROC 方法的 层次化扩展 。 该模型直接对诊断准确性和阈值进行参数化,更适合探索阈值效应对诊断性能的影响。
模型的核心参数包括:
- Λ (Lambda) — 总体准确性参数(accuracy parameter), 反映诊断测试在所有阈值下的整体区分能力
- Θ (Theta) — 总体阈值参数(threshold/positivity parameter), 反映阈值设定的整体趋势
- β (beta) — 非对称性参数(shape parameter), 当 β = 0 时 SROC 曲线关于反对角线对称
- σ 2 α 和 σ 2 θ — 研究间准确性方差和阈值方差
HSROC 模型与双变量模型在 无协变量 时数学等价 (Harbord et al., 2007),但两者的参数化方式不同,因此在研究问题侧重点上各有适用场景: 双变量模型更适合直接报告合并灵敏度/特异度,而 HSROC 模型更适合绘制 SROC 曲线和探索阈值效应。
双变量模型与 HSROC 模型的关系
关键结论(Harbord et al., 2007; Cochrane Handbook Chapter 9)
- 在无协变量的情况下,双变量模型和 HSROC 模型产生 等价的推断结果
- 双变量模型的参数可以唯一映射到 HSROC 模型的参数,反之亦然
- 当主要目的是报告 合并灵敏度和合并特异度 时,推荐使用双变量模型参数化
- 当主要目的是拟合 SROC 曲线 或探索阈值效应时,推荐使用 HSROC 参数化
-
本工具基于 R 包
mada实现双变量随机效应模型拟合,同时提供 SROC 曲线可视化
核心参考文献
-
双变量模型(必引):
Reitsma JB, Glas AS, Rutjes AWS, Scholten RJPM, Bossuyt PM, Zwinderman AH. Bivariate analysis of sensitivity and specificity produces informative summary measures in diagnostic reviews. J Clin Epidemiol. 2005;58(10):982–990. doi: 10.1016/j.jclinepi.2005.02.022 -
HSROC 模型(必引):
Rutter CM, Gatsonis CA. A hierarchical regression approach to meta-analysis of diagnostic test accuracy evaluations. Stat Med. 2001;20(19):2865–2884. doi: 10.1002/sim.942 -
两模型等价性证明:
Harbord RM, Deeks JJ, Egger M, Whiting P, Sterne JAC. A unification of models for meta-analysis of diagnostic accuracy studies. Biostatistics. 2007;8(2):239–251. doi: 10.1093/biostatistics/kxl004 -
Cochrane 诊断试验方法学手册:
Deeks JJ, Bossuyt PM, Leeflang MM, Takwoingi Y (editors). Cochrane Handbook for Systematic Reviews of Diagnostic Test Accuracy. Version 2.0. 2023. doi: 10.1002/9781119756194 -
SROC 曲线经典方法:
Moses LE, Shapiro D, Littenberg B. Combining independent studies of a diagnostic test into a summary ROC curve: data-analytic approaches and some additional considerations. J Clin Epidemiol. 1993;46(10):1295–1309. doi: 10.1016/0895-4356(93)90101-7 -
R mada 包:
Doebler P. mada: Meta-Analysis of Diagnostic Accuracy. R package. 2020. https://CRAN.R-project.org/package=mada
方法学描述模板(可直接用于论文)
We performed the meta-analysis of diagnostic test accuracy using the bivariate random-effects model (Reitsma et al., 2005), which jointly models the logit-transformed sensitivity and specificity across studies, accounting for both within-study sampling variability and between-study heterogeneity. This approach preserves the inherent negative correlation between sensitivity and specificity arising from threshold variation. Pooled estimates of sensitivity, specificity, positive likelihood ratio (LR+), negative likelihood ratio (LR−), and diagnostic odds ratio (DOR) with 95% confidence intervals were calculated. A summary receiver operating characteristic (SROC) curve was constructed based on the hierarchical model (Rutter & Gatsonis, 2001), with 95% confidence and prediction regions plotted to illustrate the uncertainty around the summary operating point and the expected range of results for a future study. Analyses were conducted in R (version 4.x) using the mada package (Doebler, 2020).
GRADE 参数设置
手动输入域(请根据 QUADAS 评估结果选择)
Inconsistency 和 Imprecision 将根据模型结果(I² 和 95% CI)自动估计。
GRADE 自动评估详情
• Risk of Bias:根据 QUADAS-2/3 评估结果由用户手动选择。
• Inconsistency:依据 metafor::rma (REML) 计算的 I²(Se) 和 I²(Sp) 自动判断。 均值 <25%: 0;25%∓75%: −1;>75%: −2。
• Indirectness:人群、试验方法和参考标准的适用性,由用户手动选择。
• Imprecision:依据合并 Se 和 Sp 的 95% CI 宽度自动判断。 最大 CI 宽度 <0.10: 0;0.10∓0.20: −1;>0.20: −2。
• Publication Bias:与 DTA-NMA GRADE 统一,Deeks' 检验 P < 0.10 时降 1 级;不可评估时不降级。
• 起始等级通常为 High(前瞻性诊断准确性队列研究)。
敏感性分析情境设置
敏感性分析结果表
下载 Word (.docx)
• Overall:纳入所有研究的合并估计(基于已运行的双变量模型)。
• Exclusion scenario:从原始数据中剔除选定的研究后重新拟合
mada::reitsma,并用 bootstrap (B=100) 计算 AUC 的 95% CI。• 剔除后若剩余研究 < 2,该情境将显示 —(无法拟合双变量模型)。
• 表格下方可自定义脚注(例如 'Studies excluded: Chen et al. 2020, ...')。
• 下载的 Word 文档采用 Times New Roman 字体。